Auto Blockify¶
Background¶
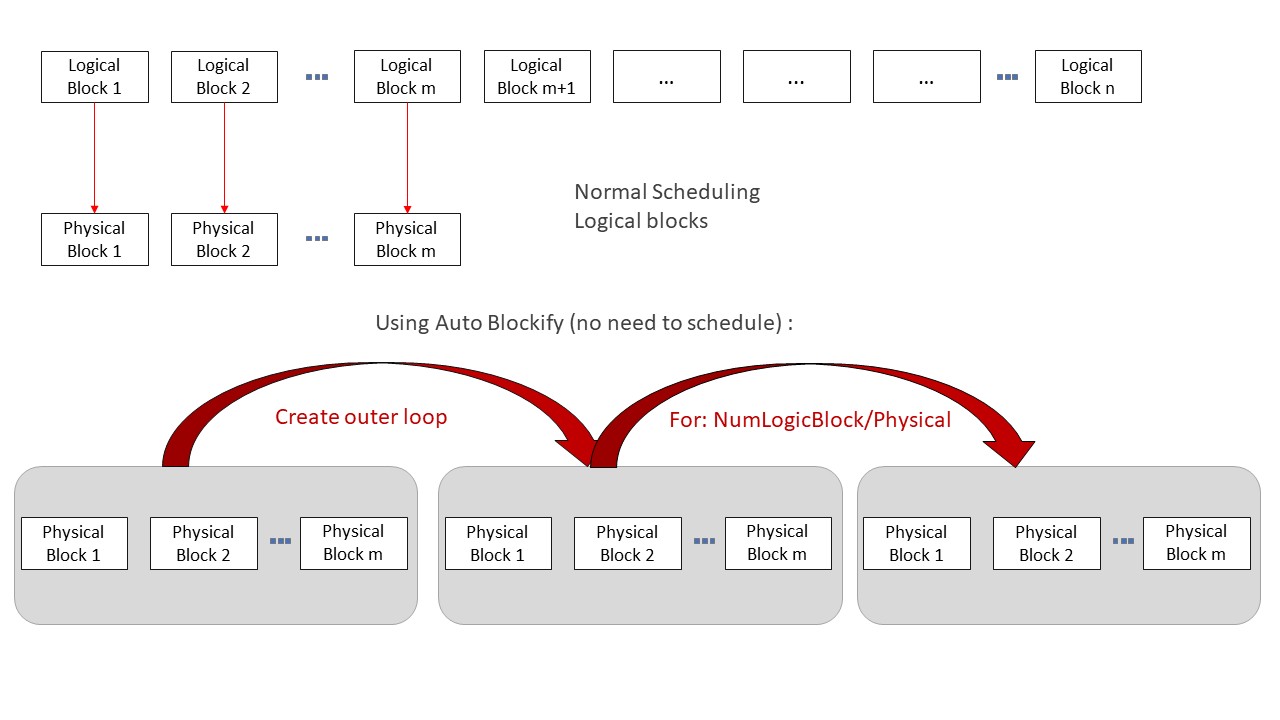
The Auto Blockify pass is essential for optimizing the execution of Ascend-compatible operators by efficiently mapping logical blocks to physical blocks in hardware. In our architecture efficient scheduling becomes crucial to performance. so when logical blocks are 1-to-1 mapped to the physical blocks scheduling would not occur and scheduling time can be saved resulting in the performance increase.
In our experience with AscendNPU IR architecture, the number of available physical blocks is often significantly lower than the number of logical blocks used in the computations. (Physical is < 50, logical may be 500+) in these 10x scenarios the acceleration can be over double the original speed.
When running a triton kernel (with triton-ascend) the way to activate the Auto Blockify logic is to add the following flag : TRITON_ALL_PARALLEL
For AscendNPU-IR user you can add the following flag to bishengir-compile command : --enable-auto-blockify-loop
Algorithm Principle¶
The Auto Blockify pass (full name: AutoBlockifyParallelLoop) transforms the IR by introducing an additional layer of looping. This is accomplished through the following logic:
for outer from 0,...,ceildiv(logical_block_dim, physical_block_dim)
for inner from 0,...,physical_block_dim <- get as block.idx
use(min(outer * physical_block_dim + inner, logical_block_dim))
Logic Explanation¶
Original Scheduling: The original pattern typically resembles:
block.idx = hivm.get_block_idx use(block.idx) -------equivalent to-------------- for block.idx from 0,...,logical_block_num use(block.idx)example usage with TRITON_ALL_PARALLEL:
When the user adds the TRITON_ALL_PARALLEL flag for triton adapter, the kernel will be launched limited to only the maximum of physical blocks (assuming logical num > physical num). Thus our execution is limited to:
for block.idx from 0,...,physical_block_num <- from get_block_idx use(block.idx)```This logic is incomplete if left alone (some indexes will be missing). this is where the auto blockify pass is needed to complete the logic by automatically adding an outer layer of looping/blockifying.
(Note: if user is not going through triton adapter they will need to make sure the block dim is set similarly as the above)
Final Logic with Auto Blockify:
for outer from 0,...,ceildiv(logical_block_dim, physical_block_dim) for inner from 0,...,physical_block_dim <- get as block.idx use(min(outer * physical_block_dim + inner, logical_block_dim))
Interface description¶
this feature is controlled in bishengir-compile with the flag --enable-auto-blockify-loop. it can be called directly with bishengir-opt using flag --auto-blockify-parallel-loop
To use this feature correctly, please note the following points:
the way the pass gets the logical block num is by finding the value marked by the attribute
kLogicalBlockNumAttr[in IR: logical_block_num] the user needs to make sure this value is available or the pass will fail when called.the pass also expects to find a hivm get_block_idx operation. this is the operation that gives the block indexes from 0 up to block dim. when using AutoBlockify user needs to change the blockdim when calling the device kernel (launch with max physical block dim, same as seen in the algorithm above). this makes it so that the blockidx operation returns values from 0,….,physical_block_num.
Triton adapter¶
This pass has been used extensively with our triton adapter pipeline. The correct way to make use of AutoBlockify feature in this case is to enable it from the front end (triton) with TRITON_ALL_PARALLEL=1 as this environment variable will also lay the foundation (lock the number of blocks) then automatically call the appropriate compiler command with the correct flags. in the triton pipeline there is a pass called TritonGlobalKernelArgsToHIVMOpPass which will automatically make sure there is value marked with logical_block_num and create the get_block_idx op needed.
Example input :
module attributes {dlti.target_system_spec = #dlti.target_system_spec<"NPU" : #hacc.target_device_spec<#dlti.dl_entry<"AI_CORE_COUNT", 20 : i32>, #dlti.dl_entry<"CUBE_CORE_COUNT", 20 : i32>, #dlti.dl_entry<"VECTOR_CORE_COUNT", 40 : i32>, #dlti.dl_entry<"UB_SIZE", 1572864 : i32>, #dlti.dl_entry<"L1_SIZE", 4194304 : i32>, #dlti.dl_entry<"L0A_SIZE", 524288 : i32>, #dlti.dl_entry<"L0B_SIZE", 524288 : i32>, #dlti.dl_entry<"L0C_SIZE", 1048576 : i32>, #dlti.dl_entry<"UB_ALIGN_SIZE", 256 : i32>, #dlti.dl_entry<"L1_ALIGN_SIZE", 256 : i32>, #dlti.dl_entry<"L0C_ALIGN_SIZE", 4096 : i32>>>, hivm.module_core_type = #hivm.module_core_type<AIV>} {
func.func @add_kernel(%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>}, %arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}, %arg2: memref<?xf32> {tt.divisibility = 16 : i32}, %arg3: memref<?xf32> {tt.divisibility = 16 : i32}, %arg4: memref<?xf32> {tt.divisibility = 16 : i32}, %arg5: i32 {tt.divisibility = 16 : i32}, %arg6: i32, %arg7: i32, %arg8: i32) attributes {WorkspaceArgIdx = 0 : i64, func_dyn_memref_args = dense<[false, true, true, true, true, false, false, false, false]> : vector<9xi1>, hacc.entry, hacc.function_kind = #hacc.function_kind<DEVICE>, hivm.func_core_type = #hivm.func_core_type<AIV>} {
%c1024 = arith.constant 1024 : index
%c1024_i32 = arith.constant 1024 : i32
%c0 = arith.constant 0 : index
hivm.hir.set_mask_norm
%0 = arith.muli %arg6, %arg7 : i32
%1 = arith.muli %0, %arg8 : i32
annotation.mark %1 {logical_block_num} : i32 // this logical_block_num is the original large number
%2 = hivm.hir.get_block_idx -> i64 // for block.idx from 0,...,block_num
%3 = arith.trunci %2 : i64 to i32
%4 = arith.muli %arg8, %arg7 : i32
%5 = arith.divsi %3, %4 : i32
%6 = arith.remsi %5, %arg6 : i32
%7 = arith.muli %6, %c1024_i32 : i32
%8 = arith.index_cast %7 : i32 to index
%reinterpret_cast = memref.reinterpret_cast %arg2 to offset: [%8], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%alloc = memref.alloc() : memref<1024xf32>
%9 = arith.addi %8, %c1024 : index
%10 = arith.index_cast %arg5 : i32 to index
%11 = arith.maxsi %8, %10 : index
%12 = arith.minsi %9, %11 : index
%13 = arith.subi %12, %8 : index
%subview = memref.subview %reinterpret_cast[0] [%13] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
%subview_0 = memref.subview %alloc[0] [%13] [1] : memref<1024xf32> to memref<?xf32, strided<[1]>>
hivm.hir.load ins(%subview : memref<?xf32, strided<[1], offset: ?>>) outs(%subview_0 : memref<?xf32, strided<[1]>>) left_padding_num = %c0 : index init_out_buffer = false
%14 = bufferization.to_tensor %alloc restrict writable : memref<1024xf32>
%reinterpret_cast_1 = memref.reinterpret_cast %arg3 to offset: [%8], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%alloc_2 = memref.alloc() : memref<1024xf32>
%subview_3 = memref.subview %reinterpret_cast_1[0] [%13] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
%subview_4 = memref.subview %alloc_2[0] [%13] [1] : memref<1024xf32> to memref<?xf32, strided<[1]>>
hivm.hir.load ins(%subview_3 : memref<?xf32, strided<[1], offset: ?>>) outs(%subview_4 : memref<?xf32, strided<[1]>>) left_padding_num = %c0 : index init_out_buffer = false
%15 = bufferization.to_tensor %alloc_2 restrict writable : memref<1024xf32>
%16 = tensor.empty() : tensor<1024xf32>
%17 = hivm.hir.vadd ins(%14, %15 : tensor<1024xf32>, tensor<1024xf32>) outs(%16 : tensor<1024xf32>) -> tensor<1024xf32>
%reinterpret_cast_5 = memref.reinterpret_cast %arg4 to offset: [%8], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%extracted_slice = tensor.extract_slice %17[0] [%13] [1] : tensor<1024xf32> to tensor<?xf32>
%subview_6 = memref.subview %reinterpret_cast_5[0] [%13] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
hivm.hir.store ins(%extracted_slice : tensor<?xf32>) outs(%subview_6 : memref<?xf32, strided<[1], offset: ?>>)
return
}
}
Example output:
module attributes {dlti.target_system_spec = #dlti.target_system_spec<"NPU" : #hacc.target_device_spec<#dlti.dl_entry<"AI_CORE_COUNT", 20 : i32>, #dlti.dl_entry<"CUBE_CORE_COUNT", 20 : i32>, #dlti.dl_entry<"VECTOR_CORE_COUNT", 40 : i32>, #dlti.dl_entry<"UB_SIZE", 1572864 : i32>, #dlti.dl_entry<"L1_SIZE", 4194304 : i32>, #dlti.dl_entry<"L0A_SIZE", 524288 : i32>, #dlti.dl_entry<"L0B_SIZE", 524288 : i32>, #dlti.dl_entry<"L0C_SIZE", 1048576 : i32>, #dlti.dl_entry<"UB_ALIGN_SIZE", 256 : i32>, #dlti.dl_entry<"L1_ALIGN_SIZE", 256 : i32>, #dlti.dl_entry<"L0C_ALIGN_SIZE", 4096 : i32>>>, hivm.module_core_type = #hivm.module_core_type<AIV>} {
func.func @add_kernel(%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>}, %arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}, %arg2: memref<?xf32> {tt.divisibility = 16 : i32}, %arg3: memref<?xf32> {tt.divisibility = 16 : i32}, %arg4: memref<?xf32> {tt.divisibility = 16 : i32}, %arg5: i32 {tt.divisibility = 16 : i32}, %arg6: i32, %arg7: i32, %arg8: i32) attributes {WorkspaceArgIdx = 0 : i64, func_dyn_memref_args = dense<[false, true, true, true, true, false, false, false, false]> : vector<9xi1>, hacc.entry, hacc.function_kind = #hacc.function_kind<DEVICE>, hivm.func_core_type = #hivm.func_core_type<AIV>} {
%0 = arith.muli %arg6, %arg7 : i32
%1 = arith.muli %0, %arg8 : i32
annotation.mark %1 {logical_block_num} : i32 // this logical_block_num is the original large number
%c0_i32 = arith.constant 0 : i32
%c40_i32 = arith.constant 40 : i32 // 40 is physical block num here
%2 = arith.ceildivsi %1, %c40_i32 : i32 // ceildiv(logical_block_num, physical_block_dim)
%c1_i32 = arith.constant 1 : i32
scf.for %arg9 = %c0_i32 to %2 step %c1_i32 : i32 { // outer loop
%c1024 = arith.constant 1024 : index
%c1024_i32 = arith.constant 1024 : i32
%c0 = arith.constant 0 : index
hivm.hir.set_mask_norm
%3 = hivm.hir.get_block_idx -> i64 // inner loop (locked to physical blocks)
%4 = arith.trunci %3 : i64 to i32
%5 = arith.muli %arg9, %c40_i32 : i32 // outer_i * physical_block_num
%6 = arith.addi %5, %4 : i32 // outer_i * physical_block_num + inner
%7 = arith.minsi %6, %1 : i32 // (min(outer*physical_block_dim + inner, logical_block_num))
%8 = arith.extsi %7 : i32 to i64
%9 = arith.trunci %8 : i64 to i32
%10 = arith.muli %arg8, %arg7 : i32
%11 = arith.divsi %9, %10 : i32
%12 = arith.remsi %11, %arg6 : i32
%13 = arith.muli %12, %c1024_i32 : i32
%14 = arith.index_cast %13 : i32 to index
%reinterpret_cast = memref.reinterpret_cast %arg2 to offset: [%14], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%alloc = memref.alloc() : memref<1024xf32>
%15 = arith.addi %14, %c1024 : index
%16 = arith.index_cast %arg5 : i32 to index
%17 = arith.maxsi %14, %16 : index
%18 = arith.minsi %15, %17 : index
%19 = arith.subi %18, %14 : index
%subview = memref.subview %reinterpret_cast[0] [%19] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
%subview_0 = memref.subview %alloc[0] [%19] [1] : memref<1024xf32> to memref<?xf32, strided<[1]>>
hivm.hir.load ins(%subview : memref<?xf32, strided<[1], offset: ?>>) outs(%subview_0 : memref<?xf32, strided<[1]>>) left_padding_num = %c0 : index
%20 = bufferization.to_tensor %alloc restrict writable : memref<1024xf32>
%reinterpret_cast_1 = memref.reinterpret_cast %arg3 to offset: [%14], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%alloc_2 = memref.alloc() : memref<1024xf32>
%subview_3 = memref.subview %reinterpret_cast_1[0] [%19] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
%subview_4 = memref.subview %alloc_2[0] [%19] [1] : memref<1024xf32> to memref<?xf32, strided<[1]>>
hivm.hir.load ins(%subview_3 : memref<?xf32, strided<[1], offset: ?>>) outs(%subview_4 : memref<?xf32, strided<[1]>>) left_padding_num = %c0 : index
%21 = bufferization.to_tensor %alloc_2 restrict writable : memref<1024xf32>
%22 = tensor.empty() : tensor<1024xf32>
%23 = hivm.hir.vadd ins(%20, %21 : tensor<1024xf32>, tensor<1024xf32>) outs(%22 : tensor<1024xf32>) -> tensor<1024xf32>
%reinterpret_cast_5 = memref.reinterpret_cast %arg4 to offset: [%14], sizes: [1024], strides: [1] : memref<?xf32> to memref<1024xf32, strided<[1], offset: ?>>
%extracted_slice = tensor.extract_slice %23[0] [%19] [1] : tensor<1024xf32> to tensor<?xf32>
%subview_6 = memref.subview %reinterpret_cast_5[0] [%19] [1] : memref<1024xf32, strided<[1], offset: ?>> to memref<?xf32, strided<[1], offset: ?>>
hivm.hir.store ins(%extracted_slice : tensor<?xf32>) outs(%subview_6 : memref<?xf32, strided<[1], offset: ?>>)
}
return
}
}
Constraints¶
Parallelizability: The Auto Blockify algorithm is only applicable when the code is fully parallelizable. This means that the computations and accesses made by the logical blocks must be safe to run in parallel without dependencies between them.
Use Case: If Logical block num is very small then we do not get any advantage from this pass.