Cube-Vector Optimization Overview¶
Hardware Background¶
This document describes the Cube–Vector (CV) optimization flow in AscendNPU IR at a high level. CV optimizations target NPU hardware such as Atlas A2/A3: they apply a series of transformations in the HIVM (Huawei Intermediate Virtual Machine) layer so that the Cube (matrix) and Vector (vector) units work together efficiently and Mix kernel execution is improved.
Terms and Background (Read First)¶
The following terms appear throughout the CV documentation. It helps to understand them before reading individual pass details.
Term |
Description |
Remarks |
|---|---|---|
HIVM |
Huawei Intermediate Virtual Machine |
A dialect in AscendNPU IR that carries NPU-oriented ops (e.g. mmadL1, fixpipe, vadd) and control flow. |
IR |
Intermediate Representation |
The compiler’s abstraction between source and machine code. This project uses Multi-Level IR (MLIR); IR is in SSA form. |
Bufferization |
Converting the tensor abstraction into concrete memory (memref) |
In the “pre-bufferization” phase, IR is still tensor-centric (logical multi-dim arrays). After bufferization, memref (memory with address/layout) is introduced. Most CV passes run in pre-bufferization, so you will see |
tensor vs memref |
tensor: logical multi-dim array, without explicit address; memref: memory region with base, stride, and shape |
In the CV process, “output” is often first represented as a tensor, then materialized via workspace (memref) or bufferization. |
Workspace |
A contiguous region of memory in GM, passed as a kernel argument at runtime |
Used for intermediate data between Cube and Vector (e.g. fixpipe output). Multiple buffers can be allocated at different offsets in the same workspace; PlanMemory computes offsets for reuse. |
Liveness |
The lifetime of a buffer from “defined/first use” to “last use” |
PlanMemory uses liveness to decide whether two buffers can overlap; if not, they can share the same base address with different offsets. |
Inplace |
The op’s output is written over the input’s storage, reusing the same buffer |
For example, vcast f16→i16 (same width); output can overwrite input, reducing alloc. PlanMemory identifies inplace ops and assigns offsets accordingly. |
AIC / AIV |
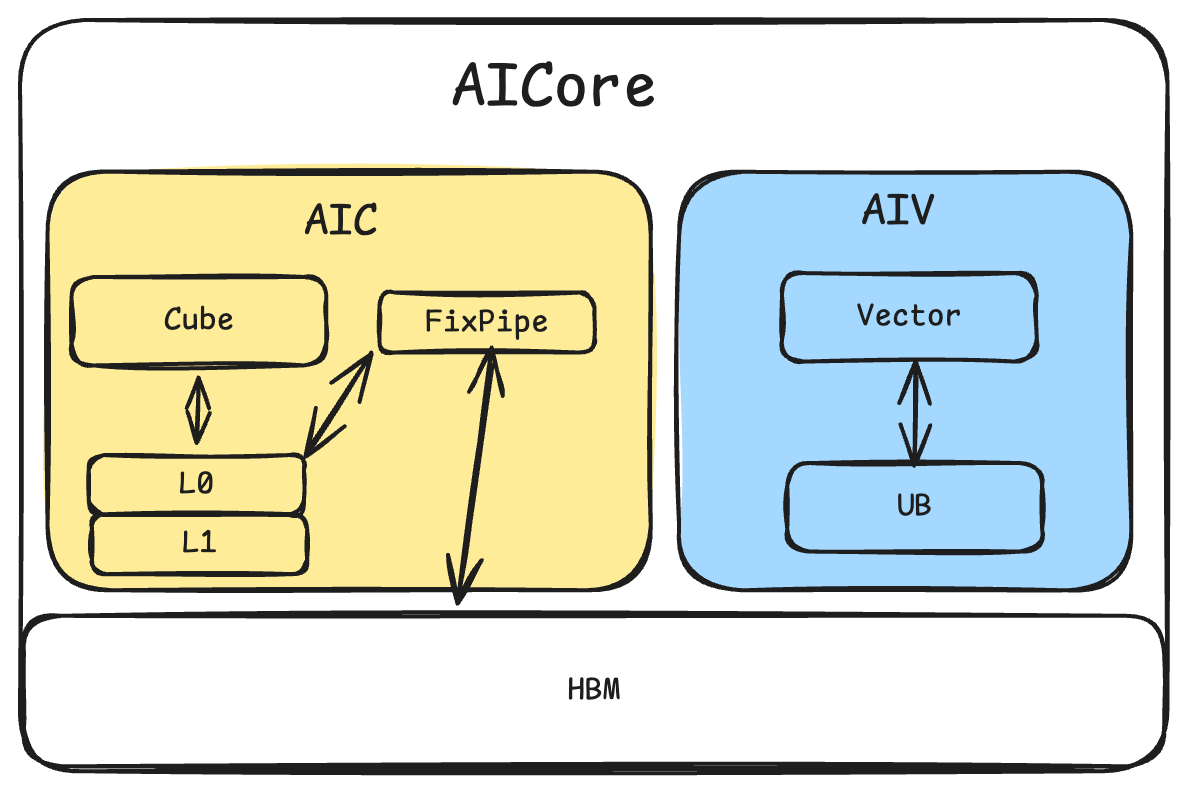
AIC: sub-kernel dominated by Cube; AIV: sub-kernel dominated by Vector |
After splitting a Mix kernel, AIC runs mainly on Cube and AIV on Vector; they exchange data via fixpipe, DMA, etc., and the host/scheduler coordinates the call order. |
Host / Device |
Host: runs on CPU; Device: runs on NPU |
Mix kernels are on the device side. “Mix can only be called from host” means the mix entry is called from a host-launched kernel call; another device kernel cannot directly call a mix function (current convention). |
CC / CV / VC / VV |
Two letters: “previous compute unit” and “next compute unit” (C=Cube, V=Vector) |
For example, CV = Cube then fixpipe/load then Vector; CC = two Cube segments connected by fixpipe+load. It is used to describe InsertWorkSpaceForMixCV patterns. |
Pre- vs post-bufferization:
Most CV passes run in the pre-bufferization phase (hivmPreBufferizationOptimizationPipeline), when IR is still tensor-centric with scf.for and similar control flow. Bufferization turns tensors into memrefs and fixes layout; after that, post-bufferization optimizations (e.g. another PlanMemory pass on memref.alloc) run. Understanding “CV structure first, then memory materialization” helps with pass ordering.
Chip Architecture¶
Ascend NPU uses a heterogeneous architecture with:
Component |
Description |
Typical Specifications (Example) |
|---|---|---|
Cube |
Matrix unit; runs |
(24 AI Cores |
Vector |
Vector unit; runs |
48 AI Cores |
L0C |
Cube output buffer for matmul results |
128 KB |
L0A/L0B |
Cube input buffer |
64 KB |
UB |
Unified buffer for vector ops |
256 KB |
GM |
Global Memory |
External DDR |
fixpipe is the data path between Cube and Vector. On Ascend, Cube and Vector are separate at the hardware level. The interaction path depends on the chip. For the 910 series, after Cube completes, fixpipe moves results from L0C to GM for later Vector use. In IR this is the hivm.hir.fixpipe op; on hardware it corresponds to the L0C→UB path and can do type conversion, quantization, etc. (controlled by fixpipe attributes such as pre_quant and pre_relu). The 910 series architecture is shown below.
Algorithm Principle¶
createNormalizeMatmulPass¶
Role: Normalize M/K/N dimensions, init conditions, and per-channel add form for
hivm.hir.mmadL1andhivm.hir.batchMmadL1.Goal: Unify matmul IR so that later fixpipe insertion, tiling, etc. can match and transform consistently.
Typical transforms: Inline vbrc+vadd-style bias into mmadL1 init; extract real M/K/N and replace constants; handle PerChannel cases.
Typical scenario: Elementwise accumulation.
Before:
%2 = ops // not 0 const
%3 = hivm.hir.mmadL1 ins(*)
outs(%2 : tensor<16x32xf32>) -> tensor<16x32xf32>
After:
%2 = ops
%3 = tensor.empty() : tensor<16x32xf32>
%4 = hivm.hir.mmadL1 ins(*)
outs(%3 : tensor<16x32xf32>) -> tensor<16x32xf32>
%5 = hivm.hir.vadd ins(%2, %4: tensor<1x32xf32>) outs(%2 : tensor<16x32xf32>)
createInlineFixpipePass¶
Role: Insert
hivm.hir.fixpipebetween mmadL1/batchMmadL1 and store; merge store+vcast etc. into fixpipe’s quant/activation options.Goal: Make Cube-to-Vector data movement explicit so that workspace allocation and load/store insertion have clear insertion points.
Typical transforms: Insert fixpipe on the use chain from mmadL1 results to store; fuse vcast (f32→f16) etc. as fixpipe
pre_quant = F322F16.Typical scenario: Pure Cube to Store.
Before:
mmadL1 -> store
After:
mmadL1 -> fixpipe
InlineFixpipe inserts fixpipe and then tries to inline ops such as hivm.vcast, hivm.vrelu, hivm.store onto the new fixpipe.
createTileBatchMMIntoLoopPass¶
Role: Expand
hivm.hir.batchMmadL1along the batch dimension into anscf.forloop; each iteration runs a singlemmadL1and fixpipe.Goal: Turn the batch dimension into a loop so that load/fixpipe/store can be indexed by batch for workspace and pipelining.
Typical transforms: TileBatchMMIntoLoop expands batchMmadL1 into a loop.
Before:
batchmmadL1 a : [batch, m ,k], b[batch, k, n]
fixpipe workspace : [batch, m, n]
After:
for batch_idx in range(batch):
mmadL1(extract_slice(a), extract_slice(b))
fixpipe(extract_slice(workspace))
createInsertLoadStoreForMixCVPass¶
Role: Insert load/store at Cube–Vector boundaries so that data flows correctly between tensor and global workspace.
Goal: Ensure correct data transfer between Cube and Vector.
Typical transforms: batchMmadL1+fixpipe rewritten to loop with mmadL1+fixpipe; extract_slice/insert_slice on inputs/outputs.
Typical scenario: Cube-Vector mix (CV pattern)
Before:
mmadL1
fixpipe
vadd
After:
mmadL1
fixpipe
load
vadd
createInsertWorkSpaceForMixCVPass¶
Role: At Cube–Vector boundaries (CC/CV/VC/VV), replace
tensor.emptywithmemref_ext.alloc_workspaceGoal: Allocate fixpipe output, store output, and other intermediates from global workspace for cross-iteration and cross-core sharing.
Patterns: CC (mmadL1→fixpipe→load→mmadL1), CV (mmadL1→fixpipe→load→vector), VC (vector→store→load→mmadL1), VV (vector→store→load→vector).
Typical scenario: Cube-Vector mix (CV pattern)
Before:
%1 = mmadL1
%2 = tensor.empty()
%3 = fixpipe ins(%1) outs(%2)
%4 = load ins(%3)
vadd (%4)
After:
%1 = mmadL1
%2 = memref_ext.alloc_workspace()
%3 = bufferization.to_tensor(%2)
%4 = fixpipe ins(%1) outs(%3)
%5 = load ins(%4)
vadd (%5)
createBindWorkSpaceArgPass¶
Role: Bind in-function
memref_ext.alloc_workspaceto the function’s workspace argument (hacc.arg_type = #hacc.arg_type<workspace>).Goal: Single source of workspace so that the runtime passes the workspace pointer as an argument and multiple kernels can share one workspace.
Prerequisites: The function must have a workspace argument;
InsertWorkSpaceForMixCVmust have insertedalloc_workspace.Typical scenario: Cube-Vector mix (CV pattern)
Before:
func.func @bind_workspace_arg(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}){
memref_ext.alloc_workspace() : memref<100xi32>
return
}
After:
func.func @bind_workspace_arg(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}){
memref_ext.alloc_workspace() from %arg1 : memref<100xi32>
return
}
createPlanMemoryPass¶
Role: In
GLOBAL_WORKSPACE_PLANmode, plan memory formemref_ext.alloc_workspace, replacingallocwithhivm.hir.pointer_cast + offset.Goal: On a given workspace base, assign offsets by liveness and inplace rules to maximize reuse and minimize total workspace size.
Typical transforms: Multiple
alloc_workspacemapped to different offsets in the same workspace; conflicting buffers allocated with different offsets.
Before:
func.func @bind_workspace_arg(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}){
memref_ext.alloc_workspace() from %arg1 : memref<100xi32>
return
}
After:
func.func @bind_workspace_arg(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>}){
memref_ext.alloc_workspace() from %arg1 offset=[0] : memref<100xi32>
return
}
createSplitMixKernelPass¶
Role: Split the Mix kernel into AIC (Cube) and AIV (Vector) sub-functions and generate the mix entry.
Goal: The backend can schedule AIC/AIV to Cube/Vector cores separately for pipelining and sync.
Typical transforms: Traverse IR by core type; put Cube code in AIC and Vector in AIV; use ·annotation.mark· for tensors passed across cores.
Before:
func.func @bind_workspace_arg(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>},
hivm.func_core_type = #hivm.func_core_type<MIX>){
mmadl1
memref_ext.alloc_workspace() from %arg1 offset=[0] : memref<100xi32>
fixpipe
load
vadd
}
After:
func.func @bind_workspace_arg_aic(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>},
hivm.func_core_type = #hivm.func_core_type<AIC>){
mmadl1
memref_ext.alloc_workspace() from %arg1 offset=[0] : memref<100xi32>
fixpipe
}
func.func @bind_workspace_arg_aiv(
%arg0: i64 {hacc.arg_type = #hacc.arg_type<ffts_base_address>},
%arg1: memref<?xi8> {hacc.arg_type = #hacc.arg_type<workspace>},
hivm.func_core_type = #hivm.func_core_type<AIV>){
load
vadd
}
API¶
Testing individual passes:
bishengir-opt -hivm-normalize-matmul input.mlir -o output.mlir
bishengir-opt -hivm-inline-fixpipe input.mlir -o output.mlir
bishengir-opt --hivm-tile-batchmm-into-loop input.mlir -o output.mlir
bishengir-opt -insert-workspace-for-mix-cv input.mlir -o output.mlir
bishengir-opt --hivm-bind-workspace-arg input.mlir -o output.mlir
bishengir-opt -hivm-plan-memory -mem-plan-mode=global-work-space-plan input.mlir -o output.mlir
bishengir-opt -hivm-split-mix-kernel input.mlir -o output.mlir
Test cases¶
Currently, all test cases in the repository are located under path-to-ascendnpuir\bishengir\test. To run a specific pass, search for the corresponding compile command to locate the relevant test file. For example, searching for hivm-normalize-matmul will lead you to the corresponding test file bishengir\test\Dialect\HIVM\normalize-matmul.mlir.
Test commands¶
The specific run commands are provided at the top of each test file. For example:
// RUN: bishengir-opt -hivm-normalize-matmul %s -split-input-file -verify-diagnostics -allow-unregistered-dialect | FileCheck %s
Here, bishengir-opt and FileCheck are binary executable files generated during compilation, located in path-to-ascendnpuir\build\bin. In the above command, %s should be replaced with the corresponding test file, such as bishengir\test\Dialect\HIVM\normalize-matmul.mlir.
The output MLIR will match the CHECK: part in the test file. The execution is successful if no CHECK failed errors are reported after testing.
Constraints¶
createPlanMemoryPass handles the space size for data interaction points. Since the total required space size is dynamically returned, there is no limitation on the size.
createInlineFixpipePass currently can only inline three types of ops: vcast, relu, and store.