Best practices¶
Performance Optimization¶
Tiling Strategy¶
Case description¶
When porting Triton kernels from GPU to NPU, the number of logical cores launched is often much larger than the number of physical cores, causing significant launch and scheduling overhead. During porting, adjust the tiling strategy to reduce the number of cores so that the number of logical cores is close to the number of physical cores. This example uses Triton.
out = torch.gather(x, dim=1, index=idx)
Input:
Input |
Shape |
|---|---|
x |
(B, C) |
idx |
(B, K) |
Output:
Output |
Shape |
|---|---|
out |
(B, K) |
Differences¶
@triton.jit
def gather_dim1_kernel(
x_ptr, # *x [B, C]
idx_ptr, # *idx[B, K]
out_ptr, # *out[B, K]
stride_xb, stride_xc,
stride_ib, stride_ik,
stride_ob, stride_ok,
B, K,
BLOCK_B: tl.constexpr,
BLOCK_K: tl.constexpr,
):
pid_b = tl.program_id(0) # 1 block per batch row
- # GPU implementation
- pid_k = tl.program_id(1) # 1 block per K-tile
- k_off = pid_k * BLOCK_K + tl.arange(0, BLOCK_K)
- mask = k_off < K
- idx = tl.load(idx_ptr + pid_b * stride_ib + k_off * stride_ik, mask=mask) # [BLOCK_K]
- x_val = tl.load(x_ptr + pid_b * stride_xb + idx * stride_xc, mask=mask)
- tl.store(out_ptr + pid_b * stride_ob + k_off * stride_ok, x_val, mask=mask)
+ #NPU implementation
+ b_idx = pid_b * BLOCK_B + tl.arange(0, BLOCK_B)
+ b_mask = b_idx < B
+ # Loop over the K dimension
+ for k_start in range(0, K, BLOCK_K):
+ ks = tl.arange(0, BLOCK_K)
+ k_mask = ks < K - k_start
+ idx_off = (b_idx[:, None] * stride_ib +
+ (k_start + ks)[None, :] * stride_ik)
+ col_idx = tl.load(idx_ptr + idx_off, mask=b_mask[:, None] & k_mask)
+ x_off = (b_idx[:, None] * stride_xb +
+ col_idx * stride_xc)
+ x_val = tl.load(x_ptr + x_off, mask=b_mask[:, None] & k_mask)
+ out_off = (b_idx[:, None] * stride_ob +
+ (k_start + ks)[None, :] * stride_ok)
+ tl.store(out_ptr + out_off, x_val, mask=b_mask[:, None] & k_mask)
# Call
B = 128 # batch dim
K = 64
BLOCK_B = 4
BLOCK_K = 128
— # GPU
- grid = (B, triton.cdiv(K, BLOCK_K))
+ # NPU
+ grid = (triton.cdiv(B, BLOCK_B),)
Ascend-Friendly Kernel Rewriting¶
Case description¶
In the original GPU flow, i64/i32 compare operations cannot use the vector unit on NPU and fall back to scalar computation, reducing efficiency. Converting to fp32 and using vec_cast and vec_cmp enables vectorized execution.
Note: Masks in tl.load and tl.store are often auto-optimized to vector ops by the compiler; in this example tl.where requires manual conversion.
This case uses LayerNorm to illustrate vectorized compare for tail-block handling.
Differences¶
cols = tl.arange(0, BLOCK_N) # cols is int64
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
# calculate mean & rstd
mean = tl.sum(x, axis=0) / N
tl.store(Mean + row, mean)
- xbar = tl.where(cols < N, X - mean, 0.0)
+ # change cols(i64) into cols_cmp(f32) to enable vector processing
+ cols_cmp = cols.to(tl.float32)
+ xbar = tl.where(cols_cmp < N, x - mean, 0.0)
var = tl.sum(xbar * xbar, axis=0) / N
Function or Precision Cases¶
This section describes common function or precision cases.
Hang / Timeout¶
Demarcation¶
Symptom: Kernel hangs or timed out. Some hangs are related to hardware synchronization (intra-core, inter-core, or pipeline sync). If you encounter a hang, you can try passing the following options when invoking the kernel to change the binary’s sync behavior and avoid the hang.
Example:
Compile Option |
Value |
Description |
|---|---|---|
inject_barrier_all |
false(default). |
Set it to true. If the hang disappears, intra-core sync is likely the cause. This option applies to mix/aic/aiv kernels. |
inject_block_all |
false(default). |
Set it to true. If the hang disappears, inter-core sync is likely the cause. This option applies to mix kernels. |
The following uses the GDN network’s chunk_gated_delta_rule_fwd_kernel_h_blockdim64 operator as an example. Tthe original code calls it as:
chunk_gated_delta_rule_fwd_kernel_h_blockdim64[grid](
k=k,
v=u,
w=w,
v_new=v_new,
g=g,
gk=gk,
h=h,
h0=initial_state,
ht=final_state,
cu_seqlens=cu_seqlens,
chunk_offsets=chunk_offsets,
T=T,
H=H,
K=K,
V=V,
BT=BT,
)
With the CV pipeline enabled:
chunk_gated_delta_rule_fwd_kernel_h_blockdim64[grid](
k=k,
v=u,
w=w,
v_new=v_new,
g=g,
gk=gk,
h=h,
h0=initial_state,
ht=final_state,
cu_seqlens=cu_seqlens,
chunk_offsets=chunk_offsets,
T=T,
H=H,
K=K,
V=V,
BT=BT,
inject_block_all = True # Enable inter-core sync
inject_barrier_all = True # Enable intra-core sync
)
Invalid varlen arguments¶
For varlen-style kernels that randomly sample indices in seqlen, ensure that indices are valid: strictly increasing and in the range [0, seqlen].
UB overflow¶
Triton argmax: 32B alignment then axis fusion wastes UB¶
MLIR code snippet:
%reinterpret_cast = memref.reinterpret_cast %arg3 to offset: [0], sizes: [256, 9, 11], strides: [99, 11, 1] : memref<?xi8, #hivm.address_space<gm>> to memref<256x9x11xi8, strided<[99, 11, 1]>, #hivm.address_space<gm>>
%2 = hivm.hir.pointer_cast(%c0_i64) : memref<256x32x11x1xi8, #hivm.address_space<ub>>
%subview = memref.subview %2[0, 0, 0, 0] [256, 9, 11, 1] [1, 1, 1, 1] : memref<256x32x11x1xi8, #hivm.address_space<ub>> to memref<256x9x11xi8, strided<[352, 11, 1]>, #hivm.address_space<ub>>
%collapse_shape = memref.collapse_shape %reinterpret_cast [[0], [1, 2]] : memref<256x9x11xi8, strided<[99, 11, 1]>, #hivm.address_space<gm>> into memref<256x99xi8, strided<[99, 1]>, #hivm.address_space<gm>>
%collapse_shape_0 = memref.collapse_shape %subview [[0], [1, 2]] : memref<256x9x11xi8, strided<[352, 11, 1]>, #hivm.address_space<ub>> into memref<256x99xi8, strided<[352, 1]>, #hivm.address_space<ub>>
hivm.hir.load ins(%collapse_shape : memref<256x99xi8, strided<[99, 1]>, #hivm.address_space<gm>>) outs(%collapse_shape_0 : memref<256x99xi8, strided<[352, 1]>, #hivm.address_space<ub>>) init_out_buffer = false may_implicit_transpose_with_last_axis = false
Analysis:
Line 1: The original data has a shape of 256×9×11xi8 and is stored in GM (kernel argument %arg3).
Line 2: Allocate a UB buffer of size 256×32×11×1xi8 to copy data from GM to UB. The first axis is aligned to 32 bytes, and an additional dimension is appended to the last axis.
Line 3: From the UB buffer allocated in Line 2 (256×32×11×1xi8), extract a subview of shape 256×9×11xi8.
Line 4: Apply collapse_shape to the GM view in Line 1 (256×9×11xi8) to merge dimensions, resulting in a shape of 256×99xi8.
Line 5: Apply collapse_shape to the UB subview in Line 3 (256×9×11xi8) to merge dimensions, resulting in a shape of 256×99xi8.
Line 6: Copy the data from GM with shape 256×99xi8 (Line 4) to the UB buffer with shape 256×99xi8 (Line 5).
Summary:
Original data 256x9x11xi8 is 25344 B; after loading from GM to UB, UB usage (256x32x11x1xi8) is 90112 B, about 3.5× the original size.
Triton Not op: unreasonable lowering wastes UB¶
The Triton Not op is lowered in NPU IR to a sequence of VOR, VAND, VNOT, VAND; in many cases a single VNOT is sufficient.
MLIR code snippet:
%2 = hivm.hir.pointer_cast(%c0_i64) : memref<65536xi8, #hivm.address_space<ub>>
hivm.hir.load ins(%reinterpret_cast : memref<65536xi8, strided<[1]>, #hivm.address_space<gm>>) outs(%2 : memref<65536xi8, #hivm.address_space<ub>>) init_out_buffer = false may_implicit_transpose_with_last_axis = false
%3 = hivm.hir.pointer_cast(%c131072_i64) : memref<65536xi8, #hivm.address_space<ub>>
hivm.hir.vbrc ins(%c-1_i8 : i8) outs(%3 : memref<65536xi8, #hivm.address_space<ub>>)
%4 = hivm.hir.pointer_cast(%c65536_i64) : memref<65536xi8, #hivm.address_space<ub>>
hivm.hir.vor ins(%2, %3 : memref<65536xi8, #hivm.address_space<ub>>, memref<65536xi8, #hivm.address_space<ub>>) outs(%4 : memref<65536xi8, #hivm.address_space<ub>>)
%5 = hivm.hir.pointer_cast(%c0_i64) : memref<65536xi8, #hivm.address_space<ub>>
hivm.hir.vand ins(%2, %3 : memref<65536xi8, #hivm.address_space<ub>>, memref<65536xi8, #hivm.address_space<ub>>) outs(%5 : memref<65536xi8, #hivm.address_space<ub>>)
hivm.hir.vnot ins(%5 : memref<65536xi8, #hivm.address_space<ub>>) outs(%5 : memref<65536xi8, #hivm.address_space<ub>>)
%6 = hivm.hir.pointer_cast(%c65536_i64) : memref<65536xi8, #hivm.address_space<ub>>
hivm.hir.vand ins(%5, %4 : memref<65536xi8, #hivm.address_space<ub>>, memref<65536xi8, #hivm.address_space<ub>>) outs(%6 : memref<65536xi8, #hivm.address_space<ub>>)
Analysis:
Line 1: The original data has a shape of 65536xi8 and is stored in GM (kernel argument %arg3).
Line 2: Allocate a UB buffer of size 65536xi8.
Line 3: Copy the data from GM in Line 1 (65536xi8) to the UB buffer allocated in Line 2 (65536xi8).
Line 4: Allocate a UB buffer of size 65536xi8.
Line 5: Fill the UB buffer allocated in Line 4 with -1.
Line 6: Allocate a UB buffer of size 65536xi8.
Line 7: Perform a bitwise OR operation between the input data and -1, and store the result in the UB buffer allocated in Line 6.
Line 8: Allocate a UB buffer of size 65536xi8.
Line 9: Perform a bitwise AND operation between the input data and -1, and store the result in the UB buffer allocated in Line 8.
Line 10: Apply a bitwise NOT operation to the result from Line 9, and store the result back into the UB buffer allocated in Line 8.
Line 11: Allocate a UB buffer of size 65536xi8.
Line 12: Perform a bitwise AND operation between the results from Line 7 and Line 10, and store the result in the UB buffer allocated in Line 11.
Summary
A bitwise NOT operation is applied to the input data input_data. In MLIR, this is lowered to the following expression: (input_data | (-1)) & (!(input_data & (-1))).
The original data size is 65536 B. To perform the computation (input_data | (-1)) & (!(input_data & (-1))), a total of 5 × 65536 B of UB space is allocated.
Triton max_dim0 (int64): PlanMemory before HIVMLowerToLoops wastes UB¶
MLIR code snippet:
%2 = hivm.hir.pointer_cast(%c0_i64) : memref<2x4912xi64, #hivm.address_space<ub>>
%3 = hivm.hir.pointer_cast(%c78592_i64) : memref<1x4912xi64, #hivm.address_space<ub>>
%4 = hivm.hir.pointer_cast(%c117888_i64) : memref<9824xi64, #hivm.address_space<ub>>
hivm.hir.vreduce {already_initialize_init} <max> ins(%2 : memref<2x4912xi64, #hivm.address_space<ub>>) outs(%3 : memref<1x4912xi64, #hivm.address_space<ub>>) temp_buffer(%4 : memref<9824xi64, #hivm.address_space<ub>>) reduce_dims = [0]
Analysis:
Line 1: The input data has a shape of 2×4912xi64, allocated in UB, with data sourced from GM.
Line 2: The output data has a shape of 1×4912xi64, allocated in UB to store the computation result, which is finally written back to GM.
Line 3: Allocate a UB buffer of size 9824xi64 as a temporary buffer for the vreduce operation.
Line 4: For int64 inputs, the vreduce operation is later lowered to a loop-based scalar implementation, and the temp_buffer is removed.
Summary: The temp_buffer considered during the PlanMemory stage is not actually used in the final computation, which leads to a false-positive UB overflow. The temporary buffer allocation rule should be adjusted in the pre-PlanMemory allocation step.
D-cache¶
Invalid address access¶
Symptom: Inputs are valid and on the same device ID, but the kernel’s device ID is set incorrectly, so data cannot be read and D-cache read/write errors occur.
Example: Wrong:
A=torch.empty(shape, dtype)
Correct:
A=torch.empty(shape, dtype).npu()
or
DEVICE="npu:0"
A=torch.empty(shape, dtype, device=DEVICE).npu()
Use non-negative loop iter as memory index¶
Symptom: The compiler analyzes and optimizes memory access; if the index involves complex control flow (e.g. loop indices causing out-of-bounds access), the compiler may not fully handle it. Prefer using non-negative for-loop iteration arguments as memory indices.
Example: Take the GDN network’s
causal_conv1d_fwd_kernelas an example. The value ofi_win the source code may be negative. Wrong:
for i_w in tl.static_range(-W+1, 1):
p_yi = tl.make_block_ptr(x + bos * D, (T, D), (D, 1), (i_t * BT + i_w, i_d * BD), (BT, BD), (1, 0))
Correct:
for i_w in tl.static_range(W):
p_yi = tl.make_block_ptr(x + bos * D, (T, D), (D, 1), (i_t * BT + i_w - W + 1, i_d * BD), (BT, BD), (1, 0))
Memory access¶
Implicit transpose in load¶
Symptom: Implicit transpose means the load or store performs a transpose in one go, avoiding a separate transpose kernel or explicit data reorder. It is usually done by adjusting pointer shape and strides so that the access pattern swaps dimensions. This technique can save global memory bandwidth, reduce kernel launch overhead, and improve computational efficiency.
You can use tl.make_block_ptr(base, shape, strides, offsets, block_shape, order) to achieve this,
with order specifying the iteration order of the elements in the memory, or strides specifying the transposed strides.
For a matrix transpose with input A (M, K) and output B (K, M), each block can process a block of B
and load the corresponding transposed block from A (e.g. with swapped strides). You can use make_block_ptr to load from A, but set the strides to those that result in a transposed load.
Alternatively, load a normal block of A and use tl.trans before storing to B.
import torch
import triton
import triton.language as tl
@triton.jit
def transpose_kernel(
x_ptr, y_ptr,
M, N,
stride_xm, stride_xn,
stride_ym, stride_yn,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr
):
"""
Matrix transpose kernel: Y = X^T, where X has shape (M, N) and Y has shape (N, M).
Each program block processes a (BLOCK_N, BLOCK_M) tile of Y.
Implicit transposed loading is achieved by swapping the strides of the input pointer.
"""
pid_n = tl.program_id(0) # Row block index of output matrix (original column block)
pid_m = tl.program_id(1) # Column block index of output matrix (original row block)
bn = pid_n * BLOCK_N # Row start of output = Original column start
bm = pid_m * BLOCK_M # Column start of output = Original row start
# Build input pointer: use swapped strides, shape (N, M) to match transposed access
x_ptr_t = tl.make_block_ptr(
base=x_ptr,
shape=(N, M),
strides=(stride_xn, stride_xm),
offsets=(bn, bm),
block_shape=(BLOCK_N, BLOCK_M),
order=(1, 0)
)
# Build output pointer: normal row-major strides, shape (N, M)
y_ptr_b = tl.make_block_ptr(
base=y_ptr,
shape=(N, M),
strides=(stride_ym, stride_yn),
offsets=(bn, bm),
block_shape=(BLOCK_N, BLOCK_M),
order=(1, 0)
)
# Load input tile (already implicitly transposed), with boundary checks
x_tile = tl.load(x_ptr_t, boundary_check=(0, 1))
# Store to output matrix
tl.store(y_ptr_b, x_tile, boundary_check=(0, 1))
def transpose(x, y=None, BLOCK_M=64, BLOCK_N=32):
"""
Compute matrix transpose using Triton kernel.
Args:
x: torch.Tensor of shape (M, N)
y: optional output tensor of shape (N, M); if None, it will be automatically created.
BLOCK_M: block size (along the M dimension)
BLOCK_N: block size (along the N dimension)
Returns:
y: transposed tensor
"""
M, N = x.shape
if y is None:
y = torch.empty(N, M, dtype=x.dtype, device=x.device)
else:
assert y.shape == (N, M), f"y should have shape ({N}, {M}), but got {y.shape}"
# Compute the grid size.
grid = (triton.cdiv(N, BLOCK_N), triton.cdiv(M, BLOCK_M))
# Launch the kernel.
transpose_kernel[grid](
x, y,
M, N,
x.stride(0), x.stride(1),
y.stride(0), y.stride(1),
BLOCK_M=BLOCK_M, BLOCK_N=BLOCK_N
)
return y
# Create a random matrix.
x = torch.randn(512, 1024, device='npu')
# Call the transpose function.
y = transpose(x)
If no error is reported, the execution is successful.
Use mayDiscretememaccess to avoid UB overflow¶
Symptom: The causes of UB overflow vary. Apart from the tensor data type being too large, exceeding the 192 KB UB limit, another possible reason is non-contiguous memory access leading to axis expansion within the UB. Taking the
<Nx1xf32>data type as an example, because the hardware requires 32-byte alignment for the last axis, and1xf32is only 4 bytes in size, the actual size of<Nx1xf32>on the hardware is expanded to<Nx8xf32>to ensure 32-byte alignment. Regardless of the cause of UB overflow, adding themayDiscretememaccesscompile hint can degrade tensor operations to scalar operations, thereby avoiding UB overflow.Example: When rewriting operators, simply add the
compile_hintto the data involved in load/store operations. Refer to the following code snippet: For versions prior to triton-ascend 3.2.0:
# For load operations, compile_hint should be added to the loaded value.
value = tl.load(pointer)
tl.compile_hint(value, "mayDiscretememaccess")
# For store operations, compile_hint should be added to the value being stored.
tl.compile_hint(value, "mayDiscretememaccess")
tl.store(pointer, value)
For versions after triton-ascend 3.4.0, the following modification is required:
# For load operations, compile_hint should be added to the loaded value.
value = tl.load(pointer)
tl.extra.cann.extension.compile_hint(value, "mayDiscretememaccess")
# For store operations, compile_hint should be added to the value being stored.
tl.extra.cann.extension.compile_hint(value, "mayDiscretememaccess")
tl.store(pointer, value)
Example 1
b_x = tl.load(x + o_t * D + o_d[:, None], mask=(m_t & m_d[:, None]), other=0)
By adding a compile hint, tensor memory access is degraded to scalar memory access to avoid UB overflow. Refer to the following code snippet:
b_x = tl.load(x + o_t * D + o_d[:, None], mask=(m_t & m_d[:, None]), other=0)
tl.extra.cann.extension.compile_hint(b_x, "mayDiscretememaccess")
Example 2
import triton
import triton.language as tl
+ import triton.language.extra.cann.extension as extension
@triton.jit
def copy_column_major_to_row_major(
A_ptr, B_ptr,
M, N,
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr,
):
# Obtain program IDs
pid_m = tl.program_id(0)
pid_n = tl.program_id(1)
# Compute block start positions
start_m = pid_m * BLOCK_SIZE_M
start_n = pid_n * BLOCK_SIZE_N
# Create block pointer for A (column-major: strides=(1, M)). The last dimension is non-contiguous, automatically expanded.
A_block_ptr = tl.make_block_ptr(
base=A_ptr,
shape=(M, N),
strides=(1, M),
offsets=(start_m, start_n),
block_shape=(BLOCK_SIZE_M, BLOCK_SIZE_N),
order=(0, 1), # Innermost dimension is row (index 0) because of column-major.
)
# Create block pointer for B (row-major: strides=(N, 1))
B_block_ptr = tl.make_block_ptr(
base=B_ptr,
shape=(M, N),
strides=(N, 1),
offsets=(start_m, start_n),
block_shape=(BLOCK_SIZE_M, BLOCK_SIZE_N),
order=(1, 0), # Innermost dimension is column (index 1) because of row-major.
)
# Load blocks from A with bound checks (with out-of-bound positions being filled with 0)
a = tl.load(A_block_ptr, boundary_check=(0, 1))
+ # npu
+ extension.compile_hint(a, "mayDiscretememaccess")
# Store to B
tl.store(B_block_ptr, a, boundary_check=(0, 1))
Comparison of IR before and after using compile hint in Example 2
// before using tl.compile_hint(a, "mayDiscretememaccess")
module attributes {hacc.target = #hacc.target<"Ascend910B3">} {
func.func @copy_column_major_to_row_major(%arg0: memref<?xi8> , %arg1: memref<?xi8> , %arg2: memref<?xf32> {tt.divisibility = 16 : i32, tt.tensor_kind = 0 : i32} , %arg3: memref<?xf32> {tt.divisibility = 16 : i32, tt.tensor_kind = 1 : i32} , %arg4: i32 {tt.divisibility = 16 : i32} , %arg5: i32 {tt.divisibility = 16 : i32} , %arg6: i32 , %arg7: i32 , %arg8: i32 , %arg9: i32 , %arg10: i32 , %arg11: i32 ) attributes {SyncBlockLockArgIdx = 0 : i64, WorkspaceArgIdx = 1 : i64, global_kernel = "local", mix_mode = "aiv", parallel_mode = "simd"} {
%c64 = arith.constant 64 : index
%c0 = arith.constant 0 : index
%c0_i32 = arith.constant 0 : i32
%c64_i32 = arith.constant 64 : i32
%0 = arith.muli %arg9, %c64_i32 : i32
%1 = arith.muli %arg10, %c64_i32 : i32
%2 = arith.maxsi %0, %c0_i32 : i32
%3 = arith.index_cast %2 : i32 to index
%4 = arith.maxsi %1, %c0_i32 : i32
%5 = arith.index_cast %4 : i32 to index
%6 = arith.index_cast %arg5 : i32 to index
%7 = arith.muli %3, %6 : index
%8 = arith.index_cast %arg4 : i32 to index
%9 = arith.addi %7, %5 : index
%reinterpret_cast = memref.reinterpret_cast %arg3 to offset: [%9], sizes: [64, 64], strides: [%6, 1] : memref<?xf32> to memref<64x64xf32, strided<[?, 1], offset: ?>>
%10 = arith.muli %5, %8 : index
%11 = arith.addi %10, %3 : index
%reinterpret_cast_0 = memref.reinterpret_cast %arg2 to offset: [%11], sizes: [64, 64], strides: [%8, 1] : memref<?xf32> to memref<64x64xf32, strided<[?, 1], offset: ?>>
%alloc = memref.alloc() : memref<64x64xf32>
%12 = arith.divsi %11, %8 : index
%13 = arith.subi %6, %12 : index
%14 = arith.maxsi %13, %c0 : index
%15 = arith.minsi %14, %c64 : index
%16 = arith.remsi %11, %8 : index
%17 = arith.subi %8, %16 : index
%18 = arith.maxsi %17, %c0 : index
%19 = arith.minsi %18, %c64 : index
%20 = arith.subi %c0_i32, %1 : i32
%21 = arith.maxsi %20, %c0_i32 : i32
%22 = arith.index_cast %21 : i32 to index
%23 = arith.minsi %22, %15 : index
%24 = arith.subi %15, %23 : index
%25 = arith.subi %c0_i32, %0 : i32
%26 = arith.maxsi %25, %c0_i32 : i32
%27 = arith.index_cast %26 : i32 to index
%28 = arith.minsi %27, %19 : index
%29 = arith.subi %19, %28 : index
%subview = memref.subview %reinterpret_cast_0[0, 0] [%24, %29] [1, 1] : memref<64x64xf32, strided<[?, 1], offset: ?>> to memref<?x?xf32, strided<[?, 1], offset: ?>>
%subview_1 = memref.subview %alloc[%23, %28] [%24, %29] [1, 1] : memref<64x64xf32> to memref<?x?xf32, strided<[64, 1], offset: ?>>
memref.copy %subview, %subview_1 : memref<?x?xf32, strided<[?, 1], offset: ?>> to memref<?x?xf32, strided<[64, 1], offset: ?>>
%30 = bufferization.to_tensor %alloc restrict writable : memref<64x64xf32>
%31 = tensor.empty() : tensor<64x64xf32>
%transposed = linalg.transpose ins(%30 : tensor<64x64xf32>) outs(%31 : tensor<64x64xf32>) permutation = [1, 0]
%32 = arith.divsi %9, %6 : index
%33 = arith.subi %8, %32 : index
%34 = arith.maxsi %33, %c0 : index
%35 = arith.minsi %34, %c64 : index
%36 = arith.remsi %9, %6 : index
%37 = arith.subi %6, %36 : index
%38 = arith.maxsi %37, %c0 : index
%39 = arith.minsi %38, %c64 : index
%40 = arith.minsi %27, %35 : index
%41 = arith.subi %35, %40 : index
%42 = arith.minsi %22, %39 : index
%43 = arith.subi %39, %42 : index
%extracted_slice = tensor.extract_slice %transposed[%40, %42] [%41, %43] [1, 1] : tensor<64x64xf32> to tensor<?x?xf32>
%subview_2 = memref.subview %reinterpret_cast[0, 0] [%41, %43] [1, 1] : memref<64x64xf32, strided<[?, 1], offset: ?>> to memref<?x?xf32, strided<[?, 1], offset: ?>>
bufferization.materialize_in_destination %extracted_slice in writable %subview_2 : (tensor<?x?xf32>, memref<?x?xf32, strided<[?, 1], offset: ?>>) -> ()
return
}
}
// after using tl.compile_hint(a, "mayDiscretememaccess")
module attributes {hacc.target = #hacc.target<"Ascend910B3">} {
func.func @copy_column_major_to_row_major(%arg0: memref<?xi8> , %arg1: memref<?xi8> , %arg2: memref<?xf32> {tt.divisibility = 16 : i32, tt.tensor_kind = 0 : i32} , %arg3: memref<?xf32> {tt.divisibility = 16 : i32, tt.tensor_kind = 1 : i32} , %arg4: i32 {tt.divisibility = 16 : i32} , %arg5: i32 {tt.divisibility = 16 : i32} , %arg6: i32 , %arg7: i32 , %arg8: i32 , %arg9: i32 , %arg10: i32 , %arg11: i32 ) attributes {SyncBlockLockArgIdx = 0 : i64, WorkspaceArgIdx = 1 : i64, global_kernel = "local", mix_mode = "aiv", parallel_mode = "simd"} {
%c0_i32 = arith.constant 0 : i32
%c64 = arith.constant 64 : index
%c1 = arith.constant 1 : index
%c0 = arith.constant 0 : index
%c64_i32 = arith.constant 64 : i32
%0 = arith.muli %arg9, %c64_i32 : i32
%1 = arith.muli %arg10, %c64_i32 : i32
%2 = arith.extsi %arg5 : i32 to i64
%3 = arith.maxsi %1, %c0_i32 : i32
%4 = arith.index_cast %3 : i32 to index
%5 = arith.maxsi %0, %c0_i32 : i32
%6 = arith.index_cast %5 : i32 to index
%7 = arith.index_cast %arg4 : i32 to index
%8 = arith.muli %4, %7 : index
%9 = arith.index_cast %arg5 : i32 to index
%10 = arith.addi %8, %6 : index
%reinterpret_cast = memref.reinterpret_cast %arg2 to offset: [%10], sizes: [64, 64], strides: [%7, 1] : memref<?xf32> to memref<64x64xf32, strided<[?, 1], offset: ?>>
%alloc = memref.alloc() : memref<64x64xf32>
%11 = arith.divsi %10, %7 : index
%12 = arith.subi %9, %11 : index
%13 = arith.maxsi %12, %c0 : index
%14 = arith.minsi %13, %c64 : index
%15 = arith.remsi %10, %7 : index
%16 = arith.subi %7, %15 : index
%17 = arith.maxsi %16, %c0 : index
%18 = arith.minsi %17, %c64 : index
%19 = arith.subi %c0_i32, %1 : i32
%20 = arith.maxsi %19, %c0_i32 : i32
%21 = arith.index_cast %20 : i32 to index
%22 = arith.minsi %21, %14 : index
%23 = arith.subi %14, %22 : index
%24 = arith.subi %c0_i32, %0 : i32
%25 = arith.maxsi %24, %c0_i32 : i32
%26 = arith.index_cast %25 : i32 to index
%27 = arith.minsi %26, %18 : index
%28 = arith.subi %18, %27 : index
%subview = memref.subview %reinterpret_cast[0, 0] [%23, %28] [1, 1] : memref<64x64xf32, strided<[?, 1], offset: ?>> to memref<?x?xf32, strided<[?, 1], offset: ?>>
%subview_0 = memref.subview %alloc[%22, %27] [%23, %28] [1, 1] : memref<64x64xf32> to memref<?x?xf32, strided<[64, 1], offset: ?>>
memref.copy %subview, %subview_0 : memref<?x?xf32, strided<[?, 1], offset: ?>> to memref<?x?xf32, strided<[64, 1], offset: ?>>
%29 = bufferization.to_tensor %alloc restrict writable : memref<64x64xf32>
%30 = tensor.empty() : tensor<64x64xf32>
%transposed = linalg.transpose ins(%29 : tensor<64x64xf32>) outs(%30 : tensor<64x64xf32>) permutation = [1, 0]
%31 = arith.index_cast %arg4 : i32 to index
%32 = arith.minsi %31, %c64 : index
scf.for %arg12 = %c0 to %32 step %c1 {
%33 = arith.index_cast %arg5 : i32 to index
%34 = arith.minsi %33, %c64 : index
scf.for %arg13 = %c0 to %34 step %c1 {
%35 = arith.index_cast %arg12 : index to i64
%36 = arith.extsi %0 : i32 to i64
%37 = arith.muli %2, %36 : i64
%38 = arith.muli %2, %35 : i64
%39 = arith.addi %37, %38 : i64
%40 = arith.index_cast %arg13 : index to i64
%41 = arith.extsi %1 : i32 to i64
%42 = arith.addi %39, %41 : i64
%43 = arith.addi %42, %40 : i64
%44 = arith.index_cast %43 : i64 to index
%extracted = tensor.extract %transposed[%arg12, %arg13] {DiscreteMemAccess} : tensor<64x64xf32>
%45 = tensor.empty() : tensor<1xf32>
%inserted = tensor.insert %extracted into %45[%c0] : tensor<1xf32>
%reinterpret_cast_1 = memref.reinterpret_cast %arg3 to offset: [%44], sizes: [1], strides: [1] : memref<?xf32> to memref<1xf32, strided<[1], offset: ?>>
bufferization.materialize_in_destination %inserted in writable %reinterpret_cast_1 : (tensor<1xf32>, memref<1xf32, strided<[1], offset: ?>>) -> ()
} {ExtractedLoadOrStore}
} {ExtractedLoadOrStore}
return
}
}
Scenario-based Debugging¶
This section gives guidance on Triton NPU kernel performance tuning.
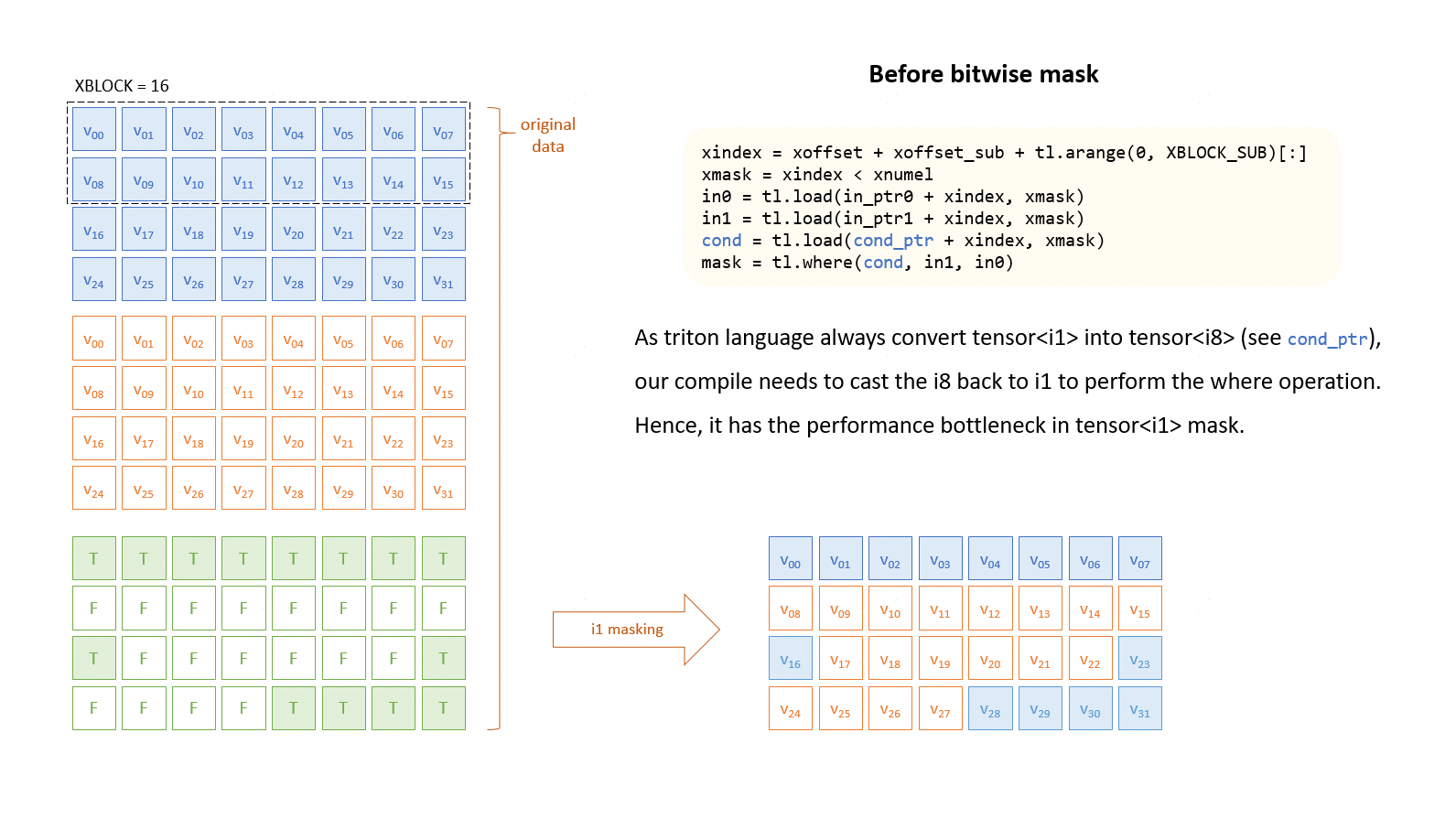
Use bitwise_mask for Mask Memory¶
Symptom¶
On Ascend, boolean (i1) tensors are stored in GM as i8 (one byte). Triton Ascend loads i1 as i8;
when the value is used as a condition mask (e.g. in tl.where), it may be converted back to i1, causing extra conversions and overhead.
The compile_hint("bitwise_mask") tells the compiler to treat the tensor as a bitmask and use bitwise ops, avoiding conversions.
To use this hint, simply add compile_hint("bitwise_mask") to the result of where. Refer to the following code snippet:
mask = tl.where(cond, value1, value2)
tl.compile_hint(cond, "bitwise_mask")
Note that since the mask is expressed as a bitmask, the mask pointer offsets must be correctly computed.

Note
When using compile_hint, pay attention to the triton-ascend version.
Before triton-ascend 3.2.0: tl.compile_hint(cond, “bitwise_mask”)
After triton-ascend 3.4.0: tl.extra.cann.extension.compile_hint(cond, “bitwise_mask”)
The bitmask feature is available only in versions after CANN 9.0.
Example¶
Rewrite the code by referring to Ascend where kernel.
For i8 bitwise mask input, add compile_hint to the result of tl.where:
Download the dependency script from the link below, place it in the same directory as the test script, and run python3 test_bitmask.py.
triton testcommon script
# test_bitmask.py
import triton
import triton.language as tl
import torch
import torch_npu
import test_common
@triton.jit
def triton_where_lt_case1(in_ptr0, in_ptr1, cond_ptr, out_ptr0, xnumel, XBLOCK: tl.constexpr, XBLOCK_SUB: tl.constexpr):
xoffset = tl.program_id(0) * XBLOCK
for xoffset_sub in range(0, XBLOCK, XBLOCK_SUB):
xindex = xoffset + xoffset_sub + tl.arange(0, XBLOCK_SUB)[:]
xmask = xindex < xnumel
in0 = tl.load(in_ptr0 + xindex, xmask)
in1 = tl.load(in_ptr1 + xindex, xmask)
cond = tl.load(cond_ptr + xindex, xmask)
res = tl.where(cond, in1, in0)
# versions after triton-ascend 3.4.0
# tl.extra.cann.extension.compile_hint(cond, "bitwise_mask")
# versions before triton-ascend 3.2.0
tl.compile_hint(cond, "bitwise_mask")
tl.store(out_ptr0 + (xindex), res, xmask)
def test_where_lt_case1():
dtype = "float32"
shape = (1, 1024, 8)
ncore = 1
xblock = 8192
xblock_sub = 1024
if shape[-1] %8 != 0:
raise ValueError("The last dimension should be a multiple of 8")
x0 = test_common.generate_tensor(shape, dtype).npu()
x1 = test_common.generate_tensor(shape, dtype).npu()
# Run triton with i8 bitwise mask
cond_i8 = test_common.generate_tensor(shape, 'uint8').npu()
y_cal = test_common.generate_tensor(shape, dtype).npu()
triton_where_lt_case1[ncore, 1, 1](x0, x1, cond_i8, y_cal, x0.numel(), xblock, xblock_sub)
test_where_lt_case1()
If no error is reported, the execution is successful.
Tiling¶
The bitmask is highly related to the tiling logic, and the kernel itself has different tiling logic under different scenarios, including but not limited to (1) enabling 1:2 optimization, (2) tensor axes fusion, (3) broadcast, (4) unsupported data types in hardware, (5) non-1 grid triton kernel, etc. Since the tiling logic varies across scenarios, we have a generalized example of creating a benchmark mask (deriving an i1 benchmark mask from an i8 bitmask) for your reference. This mask creation logic does not consider specific scenarios; it is derived from the errors in the bitmask results.
Let’s say this is the original mask creation logic:
for i in range(numel // 8):
byte_value = flatten_cond_i8[i]
for bit in range(8):
flatten_cond_i1[..., i*8 + bit] = (byte_value & (1 << bit)) != 0
Assume that in a specific scenario, when the shape is (2, X, X, X), the vimdiff result is:
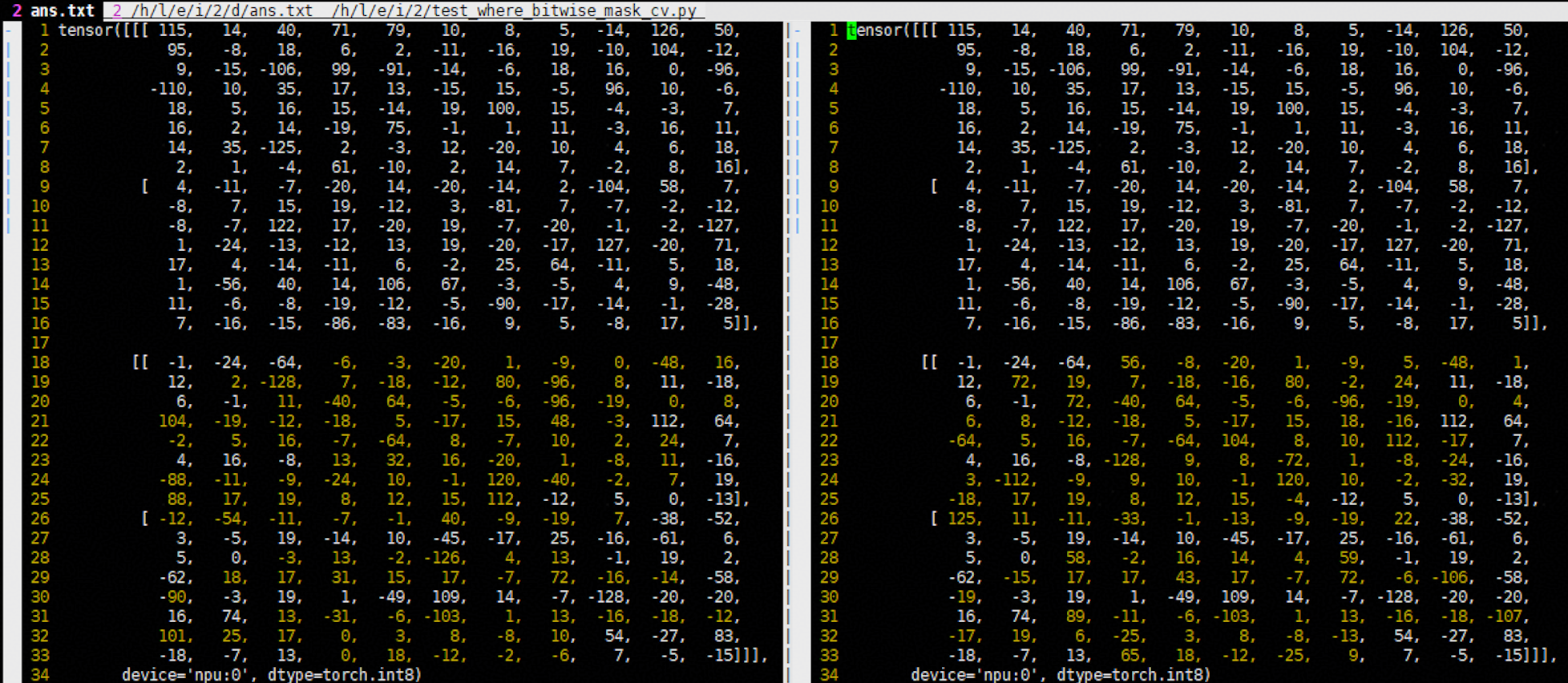
In the same scenario, when the shape is (3, X, X, X), the vimdiff result is:
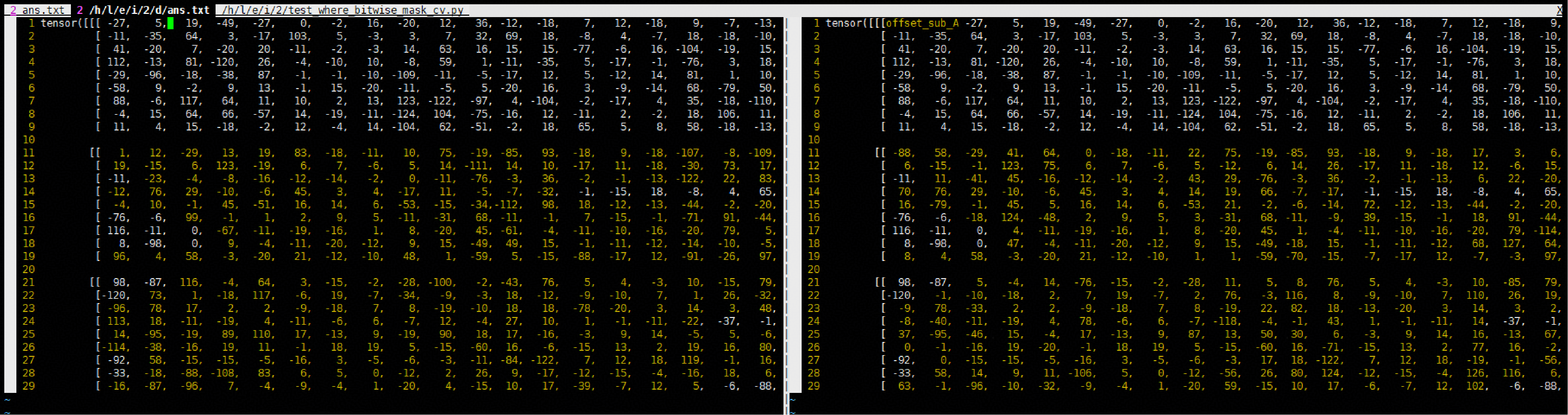
From this it can be seen that, when the shape is (A, X, X, X), the tiling logic in the preceding scenario is processed according to the first axis (i.e., A). The incorrect mask creation results in only the first tile along the first axis having aligned accuracy, while the remaining (A-1)/A of the data has deviations. Therefore, the benchmark mask creation logic for accuracy verification needs to take A into account, as shown in the following code:
for sub_A in range(A):
# The offset calculation depends on the logic of the kernel
offset_sub_A = D * B * sub_A
for i in range(min(numel, B * D) // 8):
byte_value = flatten_cond_i8[offset_sub_A + i]
for bit in range(8):
flatten_cond_i1[..., offset_sub_A + i*8 + bit] = (byte_value & (1 << bit)) != 0
Through the above mask creation example, the bitmask function can be correctly implemented using a highly generalized approach.
In addition, the following provides the logic for multi-tiling mask creation for reference:
# test_bitmask_tile.py
import triton
import triton.language as tl
import torch
import torch_npu
import pytest
import test_common
from itertools import product
def torch_where_lt_case1(x0, x1, cond):
res = torch.where(cond, x0, x1)
return res
@triton.jit
def triton_bitmask(in_ptr0, in_ptr1, cond_ptr, out_ptr0,
X_BLOCK_SIZE: tl.constexpr, Y_BLOCK_SIZE: tl.constexpr, Z_BLOCK_SIZE: tl.constexpr,
X_STRIDE: tl.constexpr, Y_STRIDE: tl.constexpr, Z_STRIDE: tl.constexpr):
# Calculate the offset according to the grid
xoffset = tl.program_id(0) * X_BLOCK_SIZE
yoffset = tl.program_id(1) * Y_BLOCK_SIZE
zoffset = tl.program_id(2) * Z_BLOCK_SIZE
xindex = X_STRIDE * (xoffset + tl.arange(0, X_BLOCK_SIZE))[:, None, None]
yindex = Y_STRIDE * (yoffset + tl.arange(0, Y_BLOCK_SIZE))[None, :, None]
zindex = Z_STRIDE * (zoffset + tl.arange(0, Z_BLOCK_SIZE))[None, None, :]
offset = xindex + yindex + zindex
# Load in0 and in1
in0 = tl.load(in_ptr0 + offset)
in1 = tl.load(in_ptr1 + offset)
cond = tl.load(cond_ptr + offset)
# bitwise where and store
mask = tl.where(cond, in0, in1)
# versions after triton-ascend 3.4.0
# tl.extra.cann.extension.compile_hint(mask, "bitwise_mask")
# versions before triton-ascend 3.2.0
tl.compile_hint(mask, "bitwise_mask")
tl.store(out_ptr0 + offset, mask)
@pytest.mark.parametrize('param_list',
[
['float32', (16, 16, 32), (2, 2, 2)],
['int32', (16, 32, 16), (2, 2, 2)],
['int16', (32, 16, 16), (2, 2, 2)],
['float16', (8, 8, 64), (8, 8, 8)],
['float32', (8, 8, 24), (4, 4, 3)],
['int32', (1, 1, 1024), (1, 1, 16)],
['int16', (1, 1, 16), (1, 1, 2)],
['float16', (8, 80, 16), (1, 80, 2)],
]
)
def test_where_lt_case1(param_list):
# Checking and constant value creation
dtype, shape, grid = param_list
if shape[0] % shape[0] != 0 or \
shape[1] % shape[1] != 0 or \
shape[2] % shape[2] != 0 :
raise ValueError("Shape is not divisible by grid")
x_block_size = shape[0] // grid[0]
y_block_size = shape[1] // grid[1]
z_block_size = shape[2] // grid[2]
if z_block_size%8 != 0:
raise ValueError("The last dimension should be a multiple of 8")
if grid[-1] == 1:
raise ValueError("Please tile the last dim")
if(dtype in ["bool", "int8", "uint8", "int64"]):
raise ValueError(f"The torch mask tiling logic is not applicable with {dtype} type")
x_stride = shape[-1] * shape[-2]
y_stride = shape[-1]
z_stride = 1
# Run triton with i8 bitwise mask
x0 = test_common.generate_tensor(shape, dtype).npu()
x1 = test_common.generate_tensor(shape, dtype).npu()
cond_i8 = test_common.generate_tensor(shape, 'uint8').npu()
y_cal = test_common.generate_tensor(shape, dtype).npu()
triton_bitmask[grid](x0, x1, cond_i8, y_cal, x_block_size, y_block_size, z_block_size, x_stride, y_stride, z_stride)
# Run torch with i1 mask
flatten_cond_bool = torch.zeros(cond_i8.flatten().shape, dtype=torch.bool).npu()
for x_block_id, y_block_id, z_block_id in product(range(grid[0]), range(grid[1]), range(grid[2])):
flatten_subview_cond_i8 = cond_i8[x_block_id * x_block_size: (x_block_id+1) * x_block_size,
y_block_id * y_block_size: (y_block_id+1) * y_block_size,
z_block_id * z_block_size: (z_block_id+1) * z_block_size].flatten()
for i in range(flatten_subview_cond_i8.shape[-1]// 8):
# Get the corresponding i8 value
i8_z_block_offset = i % (z_block_size // 8)
i8_y_block_offset = i // (z_block_size // 8) % y_block_size * z_block_size
i8_x_block_offset = i // (z_block_size // 8) // y_block_size * y_block_size * z_block_size
i8_offset = i8_z_block_offset + i8_y_block_offset + i8_x_block_offset
byte_value = flatten_subview_cond_i8[i8_offset]
# Set the corresponding i1 value
i1_z_block_offset = (z_block_id * z_block_size + (i * 8) % z_block_size) * z_stride
i1_y_block_offset = (y_block_id * y_block_size + (i * 8) // z_block_size % y_block_size) * y_stride
i1_x_block_offset = (x_block_id * x_block_size + (i * 8) // z_block_size // y_block_size) * x_stride
i1_offset = i1_x_block_offset + i1_y_block_offset + i1_z_block_offset
for bit in range(8):
flatten_cond_bool[..., i1_offset + bit] = (byte_value & (1 << bit)) != 0
cond_bool = flatten_cond_bool.view(shape)
y_ref = torch_where_lt_case1(x0, x1, cond_bool)
# Precision test
print("y_cal: ", y_cal)
print("y_ref: ", y_ref)
test_common.validate_cmp(dtype, y_cal, y_ref)
Limit¶
The Triton frontend will convert i1 to i8. Using bitwise_mask on other types (e.g. i16/i32) can hurt performance, so this feature is limited to i8.
CV¶
Using hivm.tile_mix_cube_num to avoid L1 overflow¶
Symptom¶
The compiler currently analyzes tiling for a single matmul and does not consider the lifetime of other matmuls. When matmuls are triggered multiple times (e.g. cube -> vector -> cube), overlapping lifetimes can cause L1 overflow at runtime. Until lifetime analysis is improved, use the hivm.tile_mix_cube_num compile hint so the compiler can apply sub-tiling to the relevant matmul.
Example¶
When rewriting operators, simply add the hivm.tile_mix_cube_num compile hint to the dot op result. See the following code snippet:
res = tl.dot(lhs, rhs)
tl.compile_hint(res, "hivm.tile_mix_cube_num", 2)
Take the _attn_fwd_inner operator of Flash Attention as an example. The logic for QKV matrix multiplication in the original code is roughly as follows:
qk = tl.dot(q, trans_k)
# softmax calculation in between
qk = ...
p = tl.math.exp(qk)
pv = tl.dot(p, v)
Referring to the preceding code, qk is a cube operation, while computations such as softmax are vector operations. The results computed by the vector operations are then fed into a second cube operation to perform matrix multiplication. In this scenario, the compiler cannot monitor the tiling logic within the second cube operation, and the code may cause out-of-bounds access in the L1 cache. Therefore, it is necessary to add a tile_mix_cube_num compile hint to the result of the second dot operation, instructing the compiler to perform sub-tiling on this operation, as shown in the following code snippet:
qk = tl.dot(q, trans_k)
# softmax calculation in between
qk = ...
p = tl.math.exp(qk)
pv = tl.dot(p, v)
tl.compile_hint(pv, "hivm.tile_mix_cube_num", 2)
Compile Options (Reference)¶
Option |
Meaning |
Value Range |
|---|---|---|
multibuffer |
Controls whether to enable ping-pong pipeline. |
False (default), True |
limit_auto_multi_buffer_of_local_buffer |
Scope of ping-pong on-chip (L1, L0, UB). “no-limit” = no restriction; “no-l0c” = only outside L0 cache |
“no-limit”, “no-l0c” (default) |
unit_flag |
Cube output by block (alignment scenarios only) |
False (default), True |
limit_auto_multi_buffer_only_for_local_buffer |
Controls whether to enable CV pipeline in GM workspace. False = enable. The API may change for more readable options. |
False (default), True |
set_workspace_multibuffer |
Sets the CV parallelism degree. This parameter takes effect only when |
2 (default), 4 |
tile_mix_vector_loop |
Sets the vector tile count. The value can be obtained through autotuning. This parameter takes effect only when |
1 (default), 2, 4 |
tile_mix_cube_loop |
Sets the cube tile count. The value can be obtained through autotuning. This parameter takes effect only when |
1 (default), 2, 4 |
Kernel Options to Avoid Timeout Errors¶
Symptom¶
Some hangs are related to hardware sync (intra-core, inter-core, or pipeline). You can try the following options when invoking the kernel to avoid hang:
# Sync options
inject_block_all = True # Enable inter-core sync
inject_barrier_all = True # Enable intra-core sync
# Pipeline options
limit_auto_multi_buffer_only_for_local_buffer = True # Disable CV pipeline in GM
multibuffer = False # Disable ping-pong pipeline
Example¶
Take the chunk_gated_delta_rule_fwd_kernel_h_blockdim64 operator in the GDN network as an example; the original code calls it as:
chunk_gated_delta_rule_fwd_kernel_h_blockdim64[grid](
k=k,
v=u,
w=w,
v_new=v_new,
g=g,
gk=gk,
h=h,
h0=initial_state,
ht=final_state,
cu_seqlens=cu_seqlens,
chunk_offsets=chunk_offsets,
T=T,
H=H,
K=K,
V=V,
BT=BT,
)
With the CV pipeline in GM disabled to avoid hang:
chunk_gated_delta_rule_fwd_kernel_h_blockdim64[grid](
k=k,
v=u,
w=w,
v_new=v_new,
g=g,
gk=gk,
h=h,
h0=initial_state,
ht=final_state,
cu_seqlens=cu_seqlens,
chunk_offsets=chunk_offsets,
T=T,
H=H,
K=K,
V=V,
BT=BT,
limit_auto_multi_buffer_only_for_local_buffer = True,
)
Triton NPU Programming Cases¶
Triton NPU programming reference: https://github.com/Ascend/triton-ascend-ops/blob/main/tutorial/README.zh.md