Auto-Subtiling¶
This document describes the AutoBindSubBlock pass in HIVM. This pass optimizes Cube-Vector (CV) kernels through CV 1:2 tiling. Before reading this document, you are advised to read CV Optimization to understand its terms.
Hardware Background¶
During Ascend chip evolution, AIC and AIV were separated with a 1:2 core ratio.
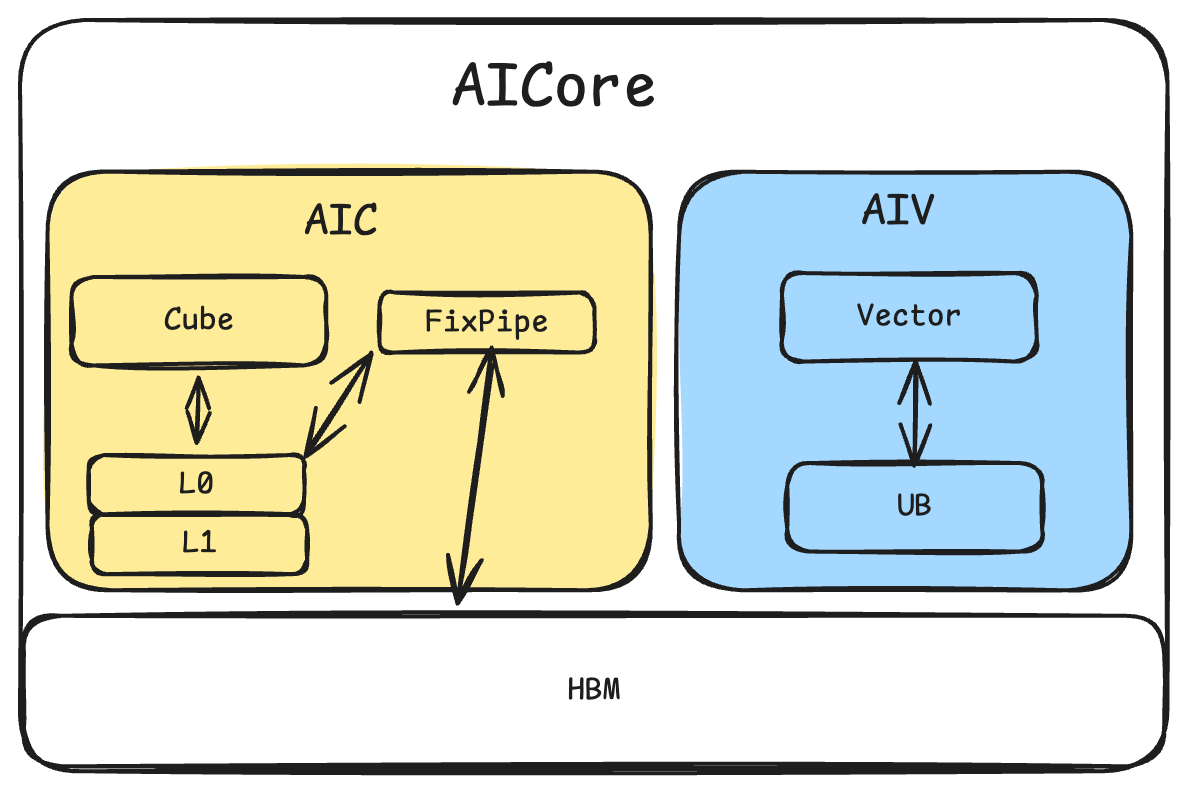
In the current ecosystem, neither user-written kernels nor community operators typically implement Ascend Cube–Vector 1:2 sub-block logic. To improve compute efficiency and Ascend affinity, the compiler needs automatic sub-block (subtiling) capability. This feature applies a Cube–Vector 1:2 subtiling strategy and performs the corresponding data splitting.
Algorithm Principle¶
The overall approach is:
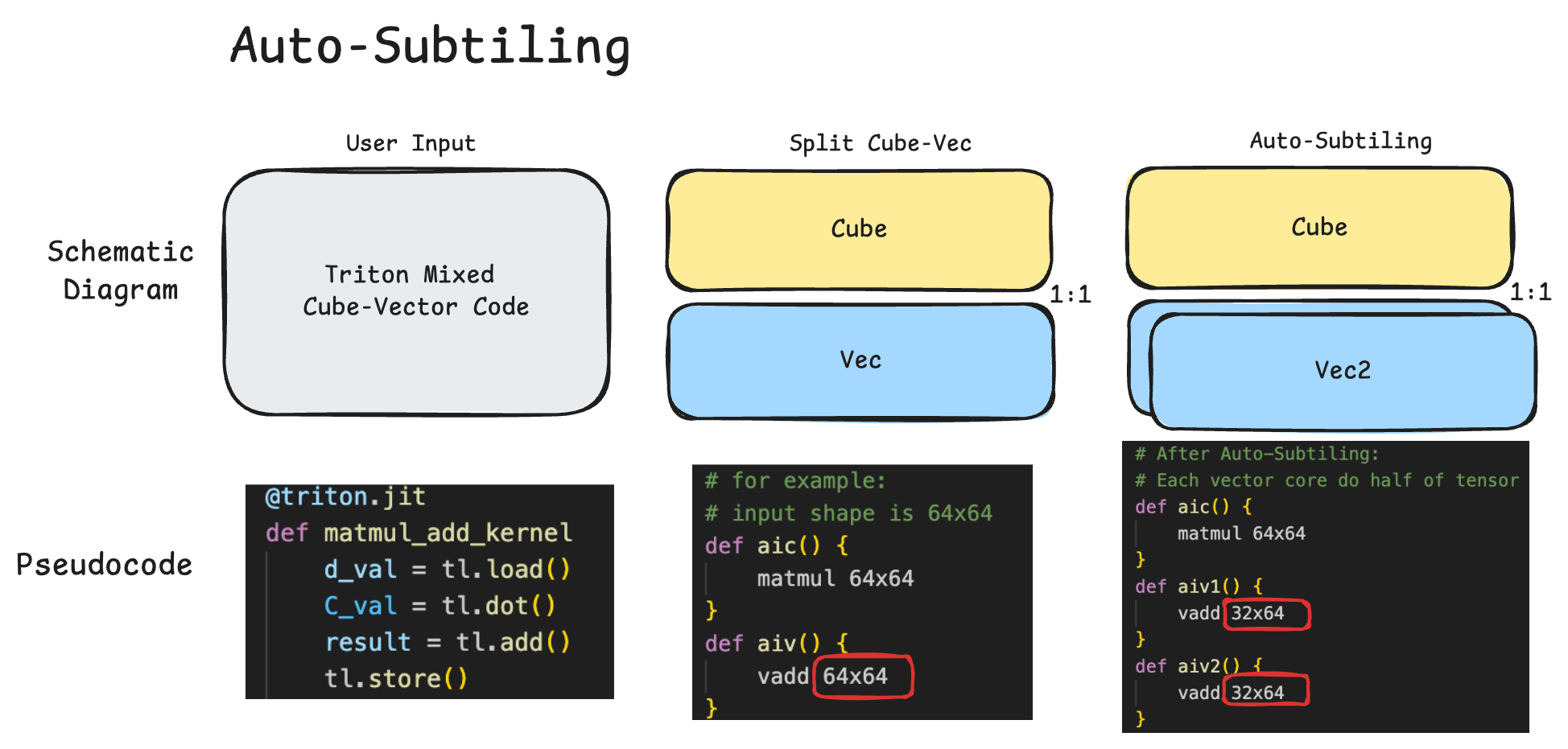
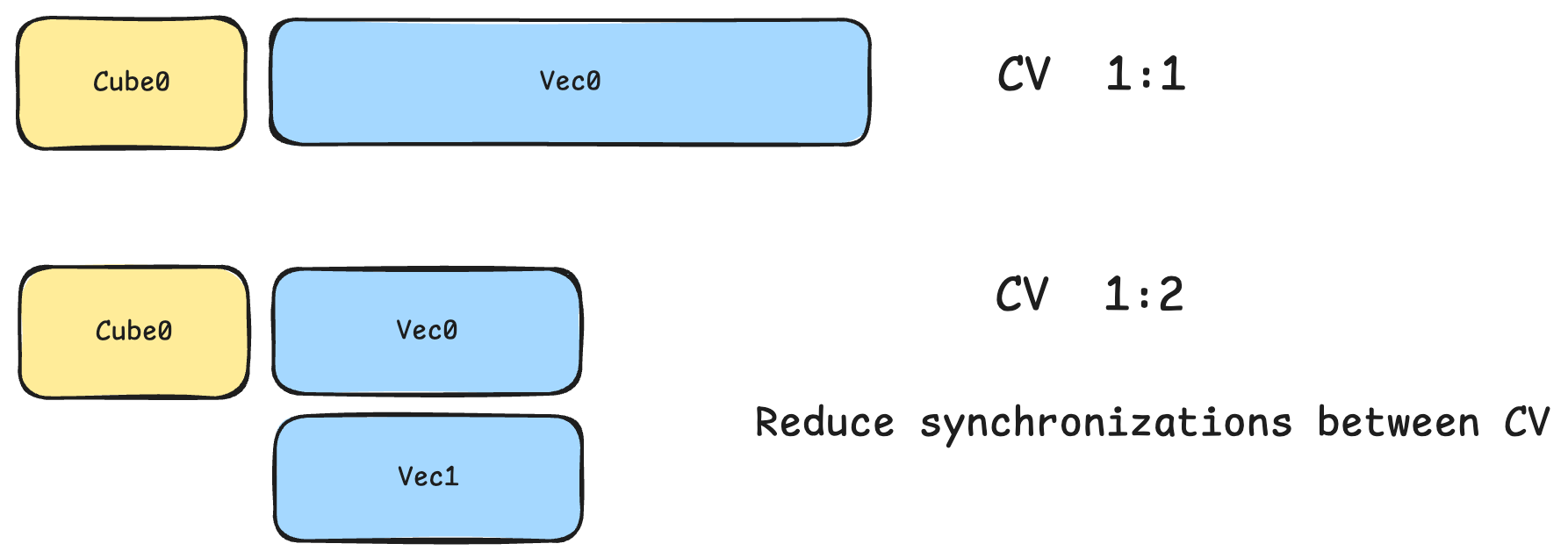
Effects:
Input/output Example¶
Original code
%t0 = hivm.hir.vexp ins(%src: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
%t1 = hivm.hir.vabs ins(%t0: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
hivm.hir.store ins(%t1: tensor<64xf16>) outs(%output : memref<64xf16>)
Vector auto 1:2 feature enabled successfully
%0 = hivm.hir.get_sub_block_idx -> i64
%slice_src = tensor.extract_slice %src[%0][32][1] : tensor<64xf16> to tensor<32xf16>
%t0 = hivm.hir.vexp ins(%slice_src: tensor<32xf16>)
outs(%new_init: tensor<32xf16>) -> tensor<32xf16>
%t1 = hivm.hir.vabs ins(%t0: tensor<32xf16>)
outs(%new_init: tensor<32xf16>) -> tensor<32xf16>
%output_slice = memref.subview %output[%0][32][1] : memref<64xf16> to memref<32xf16>
hivm.hir.store ins(%t1: tensor<32xf16>) outs(%output_slice : memref<32xf16>)
Implementation Idea¶
Split Store data in half via extract-slice and for-loop.
Bubble up the extract-slice using the BubbleUpExtractSlice pattern.
Map the for-loop to subblock.
Subtiling succeeds.
If subtiling fails, the compiler falls back to 1:1.

Figure: Auto-subtiling 1:2 implementation
Design¶
Dimension analyzer (axis selection)¶
The Dimension Analyzer chooses a parallel axis for splitting by analyzing all operators in the target kernel.
Why choose a parallel axis¶
Vector cores do not share a direct data path. To maximize parallelism and correctness, splitting must avoid cross-tile dependencies. Splitting along a parallel axis allows each tile to be computed independently on a vector unit.
Tile and slice store (leaf)¶
Before each StoreOp/leaf node, an ExtractSliceOp for 1:2 splitting is inserted along the axis chosen by the Dimension Analyzer.
BubbleUp Extract Slice¶
A BubbleUp strategy is implemented per op type. Supported op types include:
BroadcastOp, ReduceOp, ExpandOp (specific shapes), CollapseOp (specific shapes)
ElementwiseOp, LoopOp, ExtractSliceOp (specific cases), InsertSliceOp (specific cases)
Additional op types can be supported by adding matchAndRewrite patterns.
Interface¶
Behavior is controlled by:
–--enable-auto-bind-sub-block=True — enable this feature (default)
–--enable-auto-bind-sub-block=False — disable this feature
Constraints and fallback¶
If subtiling or an intermediate transformation fails, the compiler automatically falls back to 1:1 to preserve correctness.
Common reasons for falling back to 1:1:
Axis selection fails (no valid parallel axis for splitting).
BubbleUpExtractSlicePattern encounters an unsupported op.
Fallback example¶
Original code
%t0 = hivm.hir.vexp ins(%src: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
%t1 = hivm.hir.vabs ins(%t0: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
hivm.hir.store ins(%t1: tensor<64xf16>) outs(%output : memref<64xf16>)
Auto 1:2 enablement failed. With if condition, only core 0 is operational
%0 = hivm.hir.get_sub_block_idx
%1 = arith.cmpi eq %0, %c0_cst
scf.if %1 {
%t0 = hivm.hir.vexp ins(%src: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
%t1 = hivm.hir.vabs ins(%t0: tensor<64xf16>)
outs(%init: tensor<64xf16>) -> tensor<64xf16>
hivm.hir.store ins(%t1: tensor<64xf16>) outs(%output : memref<64xf16>)
}