Tile Cube and Vector Loop¶
This document describes the TileCubeVectorLoop pass in HIVM. It optimizes CV-style kernels. Before reading this document, we recommend CV Optimization for CV terminology.
Hardware Background¶
Current Ascend AI accelerator chips adopt a decoupled architecture for AIC and AIV cores. Data exchange between AIC and AIV cores is performed through Global Memory. When data dependencies exist between the AIC and AIV cores, inter-core synchronization instructions are required to ensure data correctness. However, frequent inter-core synchronization leads to performance degradation. Therefore, to improve operator execution performance, the synchronization frequency between AIC and AIV cores should be minimized as much as possible.
Function¶
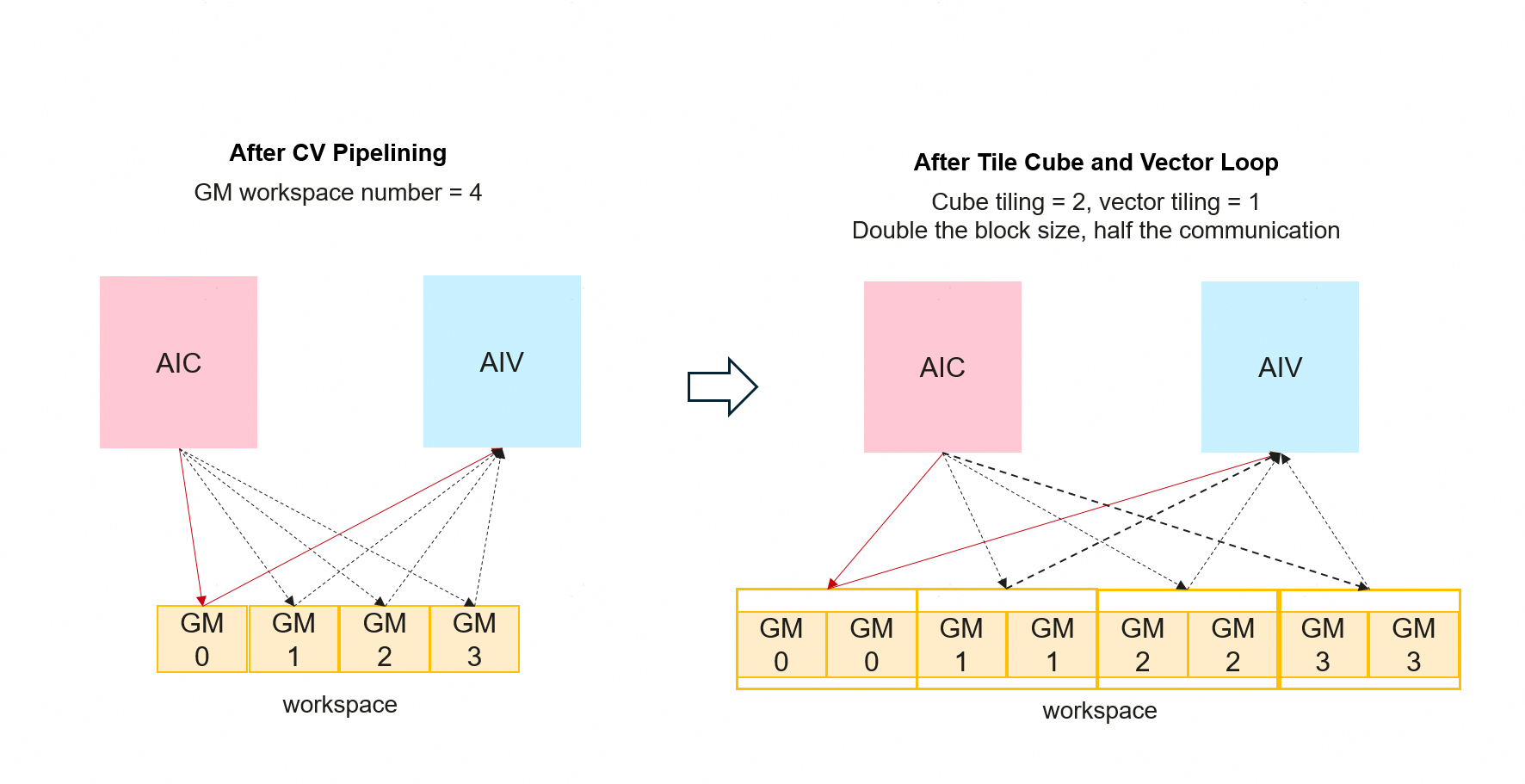
After CV Pipelining, this pass performs another tiling pass on the Cube and Vector loops in Mix kernels: it splits one large iteration into multiple smaller iterations. Goals:
Reduce inter-core sync: Smaller iterations are more likely to fit in local buffers (L0C, UB), reducing sync cost.
Coarser tiles: Under hardware limits, larger tile sizes can improve memory and compute efficiency:
Cube: Matmul results go to L0C; if one iteration exceeds L0C capacity, it cannot be placed in L0C in one shot.
Vector: Too large an iteration can cause Unified Buffer (UB) overflow.
API Description¶
Compile Options¶
Option |
Default Value |
Description |
|---|---|---|
|
1 |
Cube loop trip count; 1 means no tiling. |
|
1 |
Vector loop trip count; 1 means no tiling. |
Algorithm Principle¶
The pass walks the IR, finds CopyOut ops for Cube and Vector loops, uses them as anchors to split their producers, and fuses the split into the loop.
Before:
scf.for {
hivm.load A
hivm.load B
hivm.hir.mmadL1
hivm.hir.fixpipe
} {cube_loop}
After:
scf.for {
for {
hivm.load slice_A
hivm.load slice_B
hivm.hir.mmadL1
hivm.hir.fixpipe
} {sub_tile}
} {cube_loop}
Constraints and Capabilities¶
Only
scf.forwithhivm.loop_core_typeis processed; allowed values:#hivm.tcore_type<CUBE>: Cube loop#hivm.tcore_type<VECTOR>: vector loop
For Vector: If the tiled block size is smaller than UB alignment, no tiling is applied.
For Cube: If the block size before tiling is smaller than total L0C size, no tiling is applied. (Note: L1 size is not yet considered; L1 Memory Overflow may occur in some cases; Cube tiling will be refined with liveness analysis.)